


وقتی ترس از هوش مصنوعی، خودش به یک تهدید تبدیل میشود
هوش مصنوعی سالهاست مخالفان جدی دارد. از پژوهشگران و دانشمندانی که درباره خطرات آن هشدار…
۲۱ تیر ۱۴۰۵






۱ مرداد ۱۴۰۴
زمان مطالعه : ۶ دقیقه

در شرایطی که رقابت میان مدلهای هوش مصنوعی روز بهروز داغتر میشود، علیبابا با عرضه نسخه جدیدی از مدل زبانی Qwen3، بار دیگر توجه تحلیلگران، پژوهشگران و توسعهدهندگان در سراسر جهان را به خود جلب کرده است. این مدل جدید که نام کامل آن Qwen3-235B-A22B-Instruct-2507 به صورت متنباز در پلتفرم هاگینگفیس عرضه شده و بهبود چشمگیر عملکرد، معماری نوین و مجوز تجاری استفاده تجاری، نهتنها جایگاه چین در توسعه LLM را تثبیت میکند، بلکه چالشی جدی برای مدلهای قدرتمند شرکتهایی چون اوپنایآی، انتروپیک و گوگل است که بر رویکرد بسته و انحصاری تمرکز دارند.
به گزارش پیوست به نقل از ونچربیت، مجوز استفاده تجاری به شرکتها و توسعهدهندگان اجازه میدهد از این مدل در محصولات خود استفاده کنند. نسخه جدید Qwen3 از ۲۳۵ میلیارد پارامتر برخوردار است که البته با معماری و ساختاربندی بهینه با انرژی و توان رایانشی حداقلی میتوان از آن استفاده کرد.
طبق اعلام شرکت، نسخه FP8 که به طور ویژه برای موارد استفاده با رایانش محدود طراحی شده را میتوان تنها با ۴ پردازنده A100 استفاده کرد.
با وجود اینکه توان رایانشی کمتری برای استفاده از این مدل نیاز است، نسخه جدید Qwen3 عملکرد خود را نیز در حوزههای کلیدی تقویت کرده است:
این مدل همچنین از معماری MoE یا Mixture of Experts برای کاهش منابع رایانشی مورد نیاز کمک میگیرد و براساس این معماری تنها ۸ مسیر از ۱۲۸ مسیر تخصصی برای پاسخ به درخواست کاربر فعال میشوند.گرچه تعداد کل پارامترها ۲۳۵ میلیارد است، تنها ۲۲ میلیارد در هر لحظه فعال هستند که باعث بهینهسازی منابع مصرفی میشود.
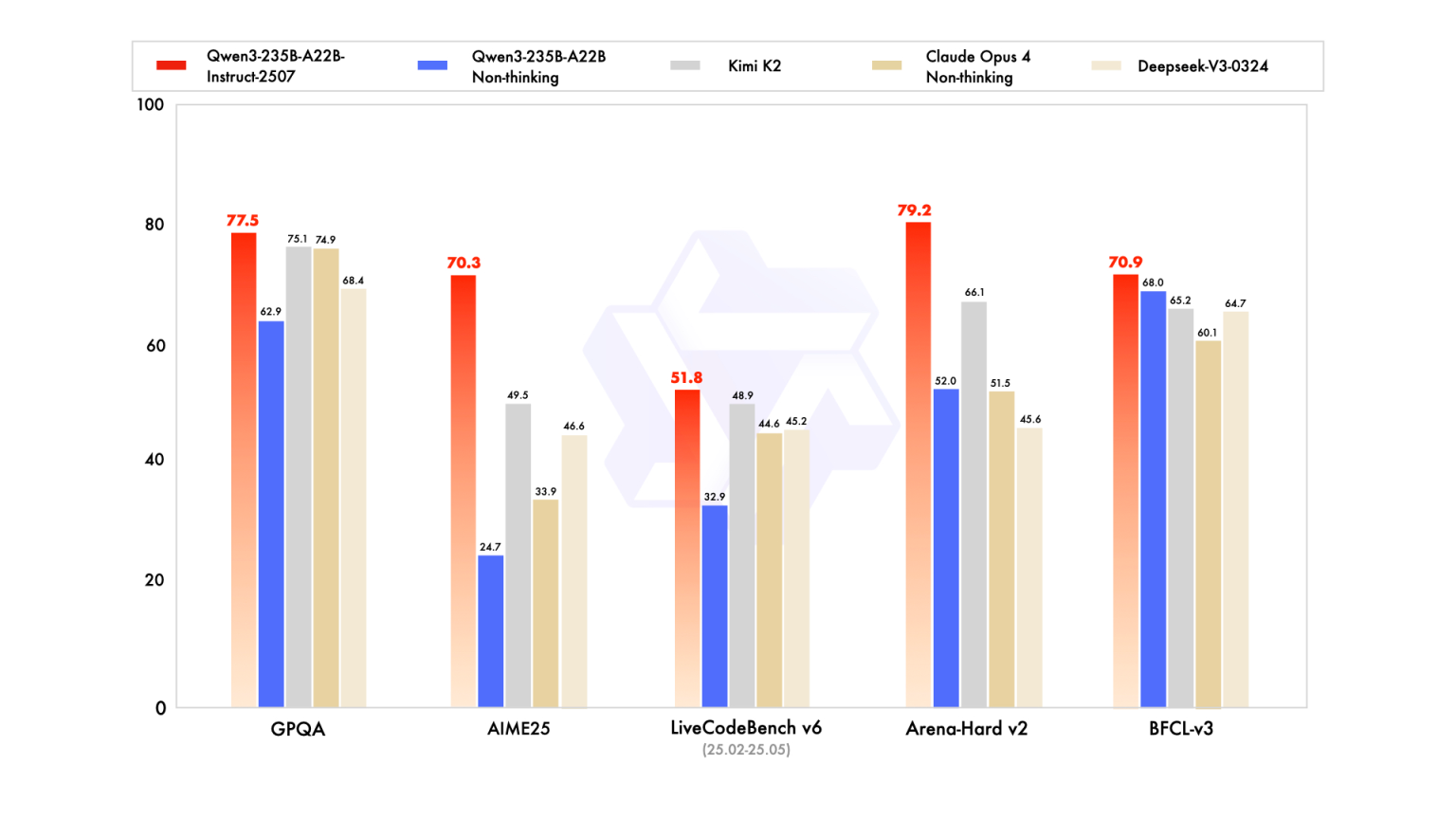
یکی از مهمترین ویژگیهای نسخه جدید، عرضه نسخهای فشردهشده بر پایه فرمت FP8 یا floating point 8-bit است. این نسخه در کنار حفظ عملکرد، مصرف حافظه، برق و منابع پردازشی را به طرز چشمگیری کاهش میدهد.
| شاخص | نسخه FP16(معمولی) | نسخه FP8 |
| حافظه GPU | ~۸۸ گیگابایت | ~۳۰ گیگابایت |
| سرعت پاسخ | ~۳۰–۴۰ توکن/ثانیه | ~۶۰–۷۰ توکن/ثانیه |
| مصرف برق | بالا | تا ۵۰٪ کمتر |
| نیاز به GPU | ۸ عدد A100 | ۴ عدد یا کمتر |
این ویژگی نسخه FP8 را به گزینهای ایدهآل برای شرکتها و تیمهایی تبدیل میکند که در محیطهایی با محدودیت منابع یا هزینه فعالیت دارند و برای مثال از ابر یا دیتاسنترهای داخلی برای اجرای مدلهای خود کمک میگیرند.
گفتنی است با وجود اینکه علیبابا در نسخه Qwen3.0 برای نخستین بار امکان استفاده از مدلهای هیبریدی را فراهم کرد که در آنها کاربر میتوانست با وارد کردن دستور /think یا فعال کردن «حالت تفکر» از مدل بخواهد ابتدا به طور زنجیرهای استدلال کند و سپس پاسخ دهد اما اکنون تیم Qwen این قابلیت را حذف کرده و طبق اعلام این تیم، مدلهای «Instruct» و «Reasoning» بهصورت جداگانه توسعه داده میشوند.
از نقطه نظر طراحی چنین تصمیمی میتواند به افزایش ثبات در رفتار مدل و ارتقای دقت در پیروی از دستور کاربر منجر شود. نسخه ۲۵۰۷ فعلا تنها مدل Instruct (غیر استدلالی) است، اما مدل reasoning نیز در راه است.
مدل Qwen3 برخلاف بسیاری از مدلهای دیگر با مجوز Apache 2.0 عرضه شده است. این بدان معناست که سازمانها میتوانند آن را آزادانه برای اهداف تجاری استفاده کنند، آن را نسبت به نیازهای خود بومیسازی کرده و روی سرورهای خصوصی اجرا کنند. برای این کار حتی نیازی به اتصال به اینترنت یا تنظیم و بهینهسازی API آن نیست.
علیبابا با عرضه این مدل با ویژگیهایی زیر سازمانها را هدف قرار داده است:
عرضه نسخه ۲۵۰۷ از همان ابتدای عرضه خود با واکنشهای بسیار مثبتی از سوی متخصصان مواجه شده است. پل کووره، بنیانگذار Blue Shell AI، عملکرد مدل را بهتر از Claude Opus 4 و Kimi K2 توصیف کرده است. جف بادیه از هاگینگ فیس نیز به مزایای FP8 از جمله امکان قابلیت اجرای سریع در Azure ML و مکبوک اشاره کرده است.
حتی برخی کاربران توییتر میگویند مدل Qwen توانسته مدل پرادعای Kimi K2 را تنها طی یک هفته به حاشیه براند و این در حالی است که حجم آن تنها یکچهارم حجم کیمی است.
تیم توسعه دهنده Qwen وعده داده که نسخههای آینده بر تواناییهای عاملمحور یا ایجنتیک تمرکز میکنند. شرکتهای هوش مصنوعی در حال حاضر حرکت به سمت عاملهای هوش مصنوعی را در اولویت قرار دادهاند و شرکت اوپنایآی نیز به تازگی از ChatGPT Agent برای اهداف مشابه رونمایی کرد.
توسعه دهندگان شرکت علیبابا میگویند رویکرد عاملمحور این مدل بر توانایی برنامهریزی بلندمدت، تعامل چندمرحلهای با ابزارها و استدلال پیچیده تمرکز میکند.
همچنین با توجه به عرضه مدلهای چندوجهی Qwen-VL و Qwen-Omni در گذشته، انتظار میرود نسخههای چندوجهی (متنی-تصویری-شنیداری) نیز براساس نسخه جدید توسعه یابند.
شایعاتی نیز درباره عرضه یک نسخه بسیار قدرتمندتر با نام Qwen3-Coder-480B-A35B-Instruct وجود دارد که احتمالا از معماری MoE با ۴۸۰ میلیارد پارامتر و کانتکست یکمیلیون توکنی بهره میگیرد. این مدل در صورت عرضه میتواند آغازگر فصل تازهای در رقابت LLMهای متنباز با توانمندی بالا باشد.
در مجموع، عرضه Qwen3-235B-A22B-Instruct-2507 علاوه بر یک ارتقای فنی، نشانهای از بلوغ مدلهای متنباز چینی و توان رقابت آنها با غولهای انحصاری غربی است. با ترکیبی از عملکرد عالی، بهرهوری، مجوز تجاری باز و قابلیت اجرا در محیطهای سازمانی، این مدل میتواند به گزینهای پیشرو در پیادهسازیهای مقیاسپذیر هوش مصنوعی بدل شود.







