
هوش مصنوعی؛ کمک درمان یا چالش درمان؟
چتباتهای هوش مصنوعی در حال تبدیل شدن به مشاور تغذیه و تناسب اندام میلیونها نفر…
۲۵ تیر ۱۴۰۵






۹ اردیبهشت ۱۴۰۴
زمان مطالعه : ۵ دقیقه

شرکت فناوری چینی علیبابا روز دوشنبه از خانواده جدید مدلهای هوش مصنوعی متنباز خود با نام Qwen3 رونمایی کرد. این سری شامل مجموعهای از مدلها است که به گفته شرکت، توان رقابت با بهترین مدلهای روز از جمله مدلهای شرکتهای آمریکایی چون اوپنایآی و گوگل را دارد و حتی در برخی زمینهها از آنها پیشی میگیرد.
به گزارش پیوست به نقل از تککرانچ، این مدلها، که بسیاری از آنها هماکنون یا بهزودی تحت مجوز آزاد در پلتفرمهای توسعه هوش مصنوعی مانند Hugging Face و GitHub برای دانلود در دسترس قرار میگیرند، از نظر اندازه دامنهای از ۰.۶ میلیارد تا ۲۳۵ میلیارد پارامتر را پوشش میدهند. (پارامترها معیاری تقریبی برای اندازهگیری توانایی حل مسئله یک مدل هستند و معمولا مدلهایی با پارامترهای بیشتر عملکرد بهتری دارند.)
رشد چشمگیر مدلهای بومی چین از جمله Qwen فشار فزایندهای بر شرکتهای آمریکایی از جمله اوپنایآی است تا فناوریهای هوش مصنوعی قدرتمندتری را روانه بازار کنند. علاوه بر این، پیشرفت چشمگیر شرکتهای چینی با وجود محدودیتهای دسترسی به پردازندههای پیشرفته باعث شده تا سیاستگذاران ایالات متحده اقداماتی را برای اعمال محدودیتهای بیشتری بر دسترسی شرکتهای چینی به تراشهها در نظر بگیرند و همین مساله باعث شده تا به تازگی صادرات پردازندههای ویژه شرکت انویدیا برای بازار چین نیز با محدودیت مواجه شود.
علیبابا میگوید مدلهای سری Qwen3 از نوع ترکیبی هستند، به این معنا که این مدلها میتوانند در مواجهه با مسائل پیچیده، زمان بیشتری را صرف «تفکر» و استدلال کنند، اما در برابر درخواستهای ساده با سرعت بالا پاسخ میدهند. این قابلیت استدلال به مدلها اجازه میدهد تا پاسخهای خود را بهنوعی صحتسنجی کنند.
رویکرد علیبابا در قبال سری Qwen3 شبیه به رویکردی است که اوپنایآی برای مدلهای o3 در پیش گرفته است، که البته تا حدی زمان پاسخگویی هوش مصنوعی را افزایش میدهد. تیم توسعهدهنده Qwen در یک پست وبلاگی در این باره گفت: «ما حالتهای تفکری و غیرتفکری را بهطور یکپارچه ادغام کردهایم که این انعطاف را در اختیار کاربران قرار میدهد تا بودجه تفکری را کنترل کنند. این طراحی به کاربران اجازه میدهد تا بودجههای مختص وظیفه را با سهولت بیشتری در نظر بگیرند.»
برخی از مدلهای Qwen3 از معماری موسوم به Mixture of Experts (MoE) یا ترکیب متخصصان استفاده میکنند که به لحاظ محاسباتی کارآمدتر است. این معماری که استفاده از آن در مدلهای شرکت دیپسیک باعث کارآمدی بالا در عین کاهش هزینهها شد، وظایف را به زیروظایف کوچکتر تقسیم میکند و آنها را به مدلهای تخصصی کوچکتر موسوم به «متخصص» واگذار میکند.
علیبابا میگوید مدلهای Qwen3 از ۱۱۹ زبان مختلف پشتیبانی میکنند و آموزش آنها با استفاده از مجموعه دادهای متشکل از حدود ۳۶ تریلیون توکن انجام گرفته است. توکنها، در واقع واحد اندازهگیری برای میزان دادههای مورد استفاده در آموزش، ورودی یا خروجی مدلها هستند و یک میلیون توکن تقریبا معادل با ۷۵۰ هزار کلمه است. این دادهها ترکیبی از کتابهای درسی، جفتهای پرسش و پاسخ، قطعهکدها، دادههای تولیدشده توسط هوش مصنوعی و دیگر منابع هستند.
پیشرفتهایی از این قبیل باعث شده تا عملکرد Qwen3 نسبت به نسخه پیشین آن، Qwen2، تا حد چشمگیری بهبود پیدا کند. اگرچه هیچیک از مدلهای Qwen3 هنوز نتوانستهاند بهوضوح از مدلهای پیشرفته اوپنایآی از جمله o3 و o4 mini پیشی بگیرند، اما عملکرد آنها بهگونهای است که بهعنوان رقبایی جدی برای همتایان آمریکایی خود مطرح میشوند.
برای مثال، بزرگترین مدل این خانواده که Qwen-3-235B-A22B نام دارد در پلتفرم برنامهنویسی Codeforces عملکردی بهتر از o3-mini را به ثبت رسانده و همچنی نتوانسته از جمنای ۲.۵ پرو شرکت گوگل نیز پیشی بگیرد.
این مدل همچنین در آزمونهای دشواری مانند نسخه جدید AIME (ارزیابی ریاضی پیشرفته) و BFCL (ارزیابی توانایی استدلال مدلها) عملکرد بهتری را نسبت به o3-mini به ثبت رسانده است.
با این حال، Qwen-3-235B-A22B هنوز بهطور عمومی منتشر نشده است. بزرگترین مدل Qwen3 که تاکنون بهصورت عمومی عرضه شده، Qwen3-32B است و به گفته علیبابا، در مقایسه با بسیاری از مدلهای هوش مصنوعی متنباز و اختصاصی، عملکرد رقابتی را به نمایش میگذارد. برای مثال این مدل در آزمونهایی مانند LiveCodeBench که به ارزیابی توانایی مدلها در برنامهنویسی میپردازد، از مدل o1 شرکت اوپنایآی پیشی گرفته است.
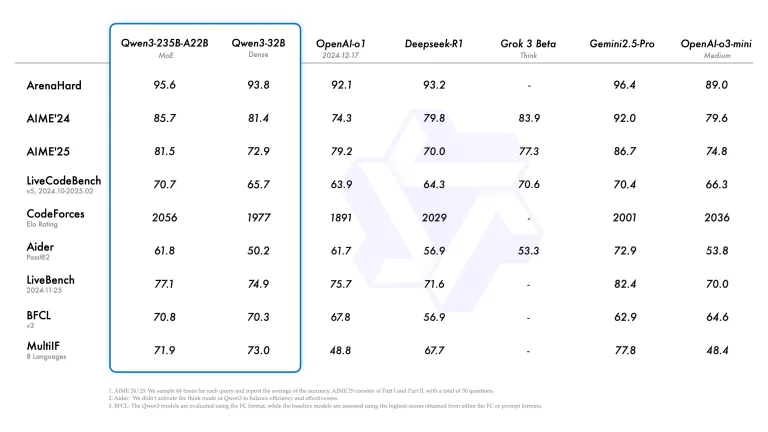
شرکت علیبابا همچنین اعلام کرده است که Qwen3 در قابلیتهایی مانند فراخوانی ابزارها (tool-calling)، پیروی دقیق از دستورالعملها و کپیبرداری از قالبهای داده عملکرد بسیار خوبی دارد. این مدلها علاوه بر امکان دانلود، از طریق ارائهدهندگان خدمات ابری نظیر Fireworks AI و Hyperbolic نیز قابل دسترسی هستند.
توهین سریواستاوا، مدیرعامل شرکت میزبان هوش مصنوعی Baseten، در مصاحبهای با تککرانچ در این باره گفت مدلهای Qwen3 نمونهای دیگری از روند مدلهای متنباز هستند که با سرعت هرچه بیشرتی فاصله خود را با مدلهای بستهای مانند ابزارهای اوپنایآی کاهش میدهند.
او میگوید: «ایالات متحده بهطور جدی در تلاش است تا فروش چیپها به چین و خرید از چین را محدود کند اما مدلهایی همچون Qwen3 که پیشرفته و متنباز هستند، بدون شک در داخل چین مورد استفاده قرار خواهند گرفت. این مسئله نشانگر این واقعیت است که کسبوکارها هم در حال ساخت ابزارهای خود هستند [و هم] در حال خرید از شرکتهای بستهای همچون انتروپیک و اوپنایآی.»
مدلهای Qwen3، بهعنوان نسل جدید مدلهای بزرگ زبانی در چین، اکنون بخشی از رقابتی جهانی در حوزه هوش مصنوعی محسوب میشوند و همچنین وزنه قدرتمند و تازهای را در اختیار فعالان متنباز و محققان مستقل قرار میدهند. این میدان رقابت نهتنها علمی و فنی، بلکه سیاسی، اقتصادی و ژئوپلتیکی نیز هست.







