




۱ تیر ۱۴۰۵


سجاد جلالی
مسعود امجدی

وحید حاجیپور
صنعت برچسبگذاری داده چیست و چه اهمیتی دارد
جنبهای ناپیدا از هوش مصنوعی
سجاد جلالی
مسعود امجدی

وحید حاجیپور
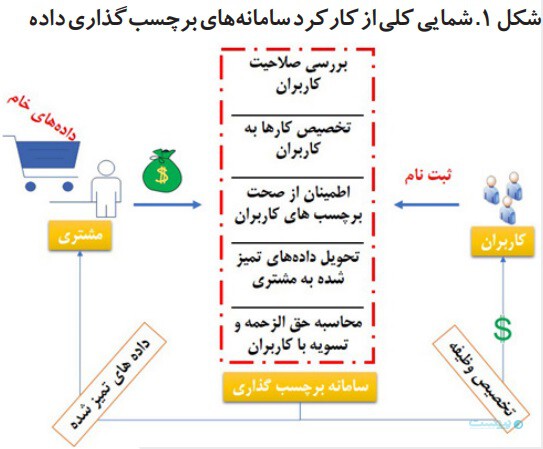
همه ماشینهای خودران بدون شک باید بدون هیچ عیب و نقصی کار کنند. تکنولوژی تشخیص سرطان و بسیاری از تجهیزات هوشمند دیگر هم همینطور هستند. نقص کم یا بینقصی عملکرد تجهیزات هوشمند، در واقع یکی از اصلیترین دلایل شکوفایی آنها در سالهای اخیر است؛ اما برای حرکت به سوی کمنقص و بیاشتباه بودن چه چیزی لازم است؟ آموزش و یادگیری از پدیدههای محیط پیرامون بیتردید موثرترین ابزار برای حرکت به سوی کاستن از نقصهای همه موجودات هوشمند است؛ برای مثال یک ماشین خودران باید از طریق یادگیری پارامترهایی نظیر اندازهها، علائم، اشکال و رنگها، درک مناسبی از آنها پیدا کند. تحقق این یادگیری در گرو آموزش ماشین خودران با استفاده از تعداد قابل توجهی دادههای درست و مرتبط با هر پارامتر است. فرض کنید ماشین خودران باید درک درستی از انواع موتورسیکلتها کسب کند؛ در این صورت باید تعداد زیادی از تصاویر موتورسیکلتهای گوناگون به الگوریتم یادگیرنده ماشین خودران تزریق شود تا با تجزیه و تحلیل آنها، بتواند یک موتورسیکلت جدید را هنگام رانندگی تشخیص و عکسالعمل لازم را نشان دهد. پرسش این است که چگونه میتوان به دادههای درست، که میتواند عکسهای متعدد از موتورسیکلتهای مختلف باشد، دسترسی پیدا کرد؟ هرچند استفاده از موتورهای جستوجو به عنوان یک شرط لازم میتواند راهگشا باشد، اما قطعاً شرط کافی نیست؛ زیرا در یک مجموعه عکس جستوجوشده از موتورسیکلت احتمالاً تصاویر نامرتبط دیگری هم وجود خواهد داشت. برای رفع این مشکل لازم است کل مجموعه داده از تصاویر مورد نظر توسط هوش انسانی بررسی و انطباق یا عدم انطباق آن با مفهوم مربوطه مشخص شود. به این بررسی و صحتسنجی در اصطلاح برچسبگذاری گفته میشود. وقتی حجم دادهها زیاد باشد، برای کوتاه کردن زمان کنترل و افزایش کیفیت خروجی کار لازم است این فرایند به جمع زیادی از کاربران سپرده شود که به آن جمعسپاری گفته میشود. فرایند برچسبگذاری به همین دلیل...

این مطلب در شماره ۸۸ پیوست منتشر شده است.
ماهنامه ۸۸ پیوست






