


پژوهش ایسپا: ۷۴ درصد کاربران از فیلترشکن استفاده میکنند
استفاده گسترده از فیلترشکن، مخالفت با قطع اینترنت و افزایش نارضایتی کاربران، سه محور اصلی…
۳۰ تیر ۱۴۰۵






۲۱ آذر ۱۴۰۲
زمان مطالعه : ۹ دقیقه

داده، عاملی مهم و موثر در پیشرفت سریع هوش مصنوعی و یادگیری ماشین است. بدون مجموعه دادههای برچسبگذاری شده با کیفیت بالا، سیستمهای یادگیری تحت نظارت به سادگی کارآمد نخواهند بود. عملیات برچسبگذاری دادهها از اهمیت بسزایی برخوردار است زیرا در صورت وجود ایراد در این مرحله باقی کار و ادامه پروژه با مشکلات جدیای مواجه میشود.
به گزارش پیوست، روشهای مختلفی برای برچسبگذاری دادهها وجود دارد. از برچسبگذاری دستی گرفته تا استفاده از دادههای هوش مصنوعی هر یک شامل مزایا و معایبی است که با توجه به این موارد و نوع فعالیت اتخاذ میشود.
دادههای برچسبدار نیاز اساسی و زمینه اصلی جهت آموزش مدلهای ML تحت نظارت است. این مدلها از دادههای برچسبگذاری شده برای یادگیری و نتیجهگیری از الگوها استفاده میکند که در نهایت میتوان آنها را برای اطلاعات بدون برچسب در دنیای واقعی اعمال کرد.
نمونههایی از کاربرد دادههای برچسبگذاری شده در این جا ذکر شده است:
دادههای تصویری: مدلهای تصویری طراحی شده در رایانهها برای تشخیص و شناسایی اقلامی که ارائه میشود مورد استفاده قرار میگیرد. این تصاویر طبقهبندی شده و مفاهیم با توجه به نوع و معیار طبقه برچسبگذاری میشود.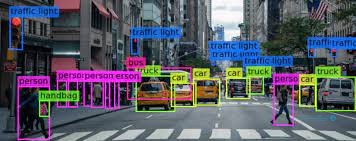
دادههای صوتی: سیستمهای پردازش زبان طبیعی(NLP) از رونوشتهای برابر با صدا برای یادگیری قابلیتهای گفتار به متن استفاده میکند.

دادههای متنی: یک مدل تحلیل احساسات ممکن است با دادههای متنی برچسبگذاری شده که شامل مجموعهای از نظرات مثبت، منفی و خنثی مخاطبان باشد طراحی و ساخته شود.

دادههای حسگر: از این مدل جهت پیشبینی خرابی ماشین آلات استفاده میشود. این مدل از روی دادههای حسگر که همراه با برچسبهایی مانند «ارتعاش زیاد» یا «دما بیش از حد» است آموزش داده شود.
بسته به نوع کاربری و حوزه استفاده میتوان مدلها را بر اساس یک یا چند نوع داده آموزش داد.
برچسبگذاری تحت تاثیر الزامات و زمینههایی که قرار است کاربرد داشته باشد صورت میگیرد. این برچسبها میتواند از طبقهبندی ساده مانند تصویر یا نام یک شی تا تقسیمبندیهای دقیقتر مبتنی بر پیکسل که اشیاء را در تصویر مشخص میکند متغیر باشد. همچنین احتمال وجود سلسله مراتب در برچسبگذاری دادهها وجود دارد. این کار که اغلب به صورت دستی توسط نیروی انسانی انجام میشود دارای مشکلات و ایراداتی از جمله امکان سوگیریهای ناخودآگاه برای آشکار کردن مجموعه دادهها و صرف مدت زمان طولانی است. البته که روشهای خودکار برای برچسبگذاری وجو دارد اما آنها نیز شامل ایرادات قابل توجهی است.
دادههای برچسبگذاری شده با کیفیت بالا برای آموزش مدلهای یادگیری تحت نظارت، بسیار مهم است و زمینه لازم برای ساخت مدلهای باکیفیت را فراهم میکند که پیشبینیهای دقیقی ارائه میدهد. در حوزه تجزیه و تحلیل دادهها و علم داده، دقت و کیفیت برچسبگذاری دادهها اغلب موفقیت و نتیجهبخشی پروژههای ML را تعیین میکند. برای کسبوکارهایی که دنبال اجرای یک پروژه تحت نظارت هستند، انتخاب روشهای مناسب برچسبگذاری داده ضروری است.
چندین روش برای برچسبگذاری دادهها وجود دارد که هر کدام شامل مزایا و معایب منحصر به فردی است. در انتخاب روش باید دقت کرد که گزینه مناسب و مفید برای نیاز و خواسته شما کدام است زیرا رویکرد برچسبگذاری انتخاب شده تاثیر قابل توجهی بر هزینه، زمان و کیفیت خواهد داشت.
برچسبگذاری دستی، خودکار، دادههای افزوده شده، دادههای مصنوعی، جمع سپاری و مجموعه دادههای از پیش برچسب گذاری شده از جمله روشهای برچسبگذاری داده به شمار میآید.
برچسبگذاری دستی: علیرغم ماهیت سخت و دشوار این نوع از برچسبگذاری، دقت، سادگی نسبی و قابلیت اطیمنان بالا موجب به کارگیری مکرر آن میشود. این امر ممکن است درون یک مجموعه انجام بپذیرد یا به ارائه دهندگان خدمات لیبلینگ حرفهای برون سپاری شود.
برچسبگذاری خودکار: در این جا روشها شامل سیستمها، اسکریپتها و الگوریتمهای مبتنی بر قانون است که میتواند به تسریع فرآیند کمک کند. یادگیری نیمه نظارتی اغلب مورد استفاده قرار میگیرد که طی آن یک مدل جداگانه روی مقادیر کمی از دادههای برچسبگذاری شده آموزش داده میشود و سپس جهت برچسبگذاری مجموعه دادههای باقی مانده استفاده میشود. ضریب خطا و احتمال نادرستی در این نوع از برچسبگذاری بسیار است به ویژه زمانی که پیچیدگی در مجموعه دادهها افزایش یابد.
دادههای افزوده شده: میتوان از طریق روشهایی جهت ایجاد تغییرات کوچک در مجموعه دادههای برچسبگذاری شده استفاده کرد و تعداد نمونههای موجود را به طور موثری افزایش داد. نکته حائز اهمیت این است که دادههای افزوده میتواند به طور بالقوه سوگیریهای موجود در دادهها را افزایش دهد.
دادههای مصنوعی: در برخی از مواقع به جای اصلاح مجموعه دادههای برچسبگذاری شده موجود، از دادههای مصنوعی ساخته فناوری هوش مصنوعی استفاده میشود. این دادهها اگر چه در افزایش حجم نمونه داده موثر به شمار میرود اما ممکن است دادههایی تولید کند که انعکاس درست واقعیت نباشد. در این جا است که اهمیت تضمین کیفیت و اعتبارسنجی مناسب بیش از پیش مشخص میشود.
جمعسپاری: این روش امکان دسترسی به حاشیه نویسان انسانی را فراهم میکند اما چالشهایی نیز در مورد آموزش، کنترل کیفیت و سوگیری نیز به وجود میآید.
مجموعه دادههای از پیش برچسبگذاری شده: این مجموعه برای کاربردهای خاصی طراحی شده است و اغلب ممکن است برای مدلهای سادهتر نیز استفاده شود.
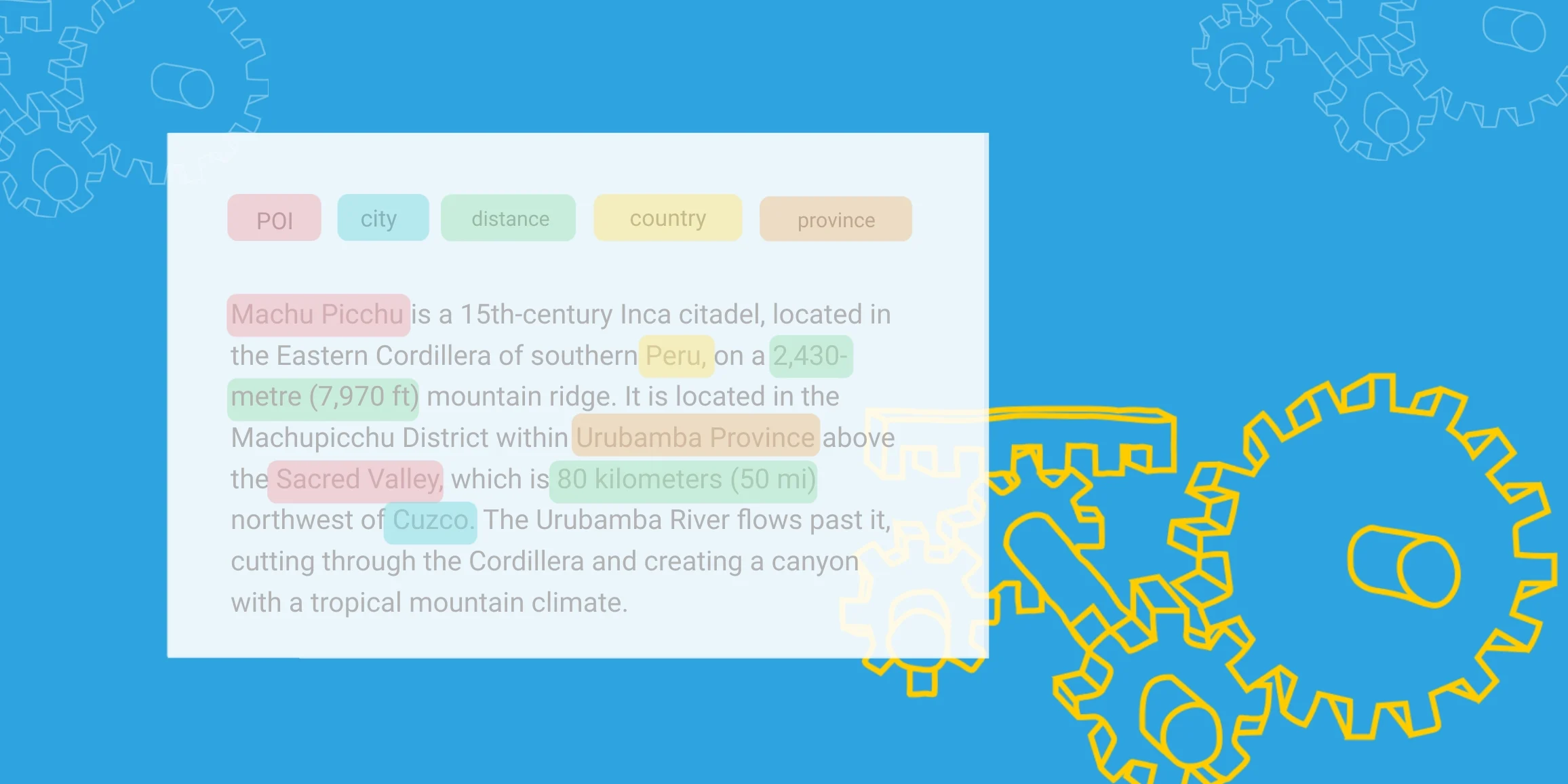
برچسبگذاری دادهها به دلیل نیاز به مقادیر زیاد داده باکیفیت با چالشهای متعددی همراه است. یکی از نگرانیهای اصلی در تحقیقات هوش مصنوعی، ماهیت متناقض برچسبگذاری دادهها است که میتواند به طور قابل توجهی بر قابلیت اطمینان و اثربخشی مدلها تاثیر بگذارد.
این موارد عبارتند از:
مقیاس پذیری: برچسبگذاری دستی دادهها مستلزم صرف تلاش و زمان قابل توجهی است که به شدت بر مقیاس پذیری تاثیر میگذارد. همچنین برچسبگذاری مبتنی بر هوش مصنوعی ممکن است بنا بر دلایلی چون هزینه زیاد یا کیفیت پایین دادهها دشواری ایجاد کند.
سوگیری: اغلب مجموعه دادههای بزرگ سوگیری دارد. طراحی برچسبهایی که سوگیری نداشته باشد میتواند عاملی برای مقابله با این نوع از برچسبها به شمار بیاید.
انتقال: ناهماهنگی میان افراد و همچنین تغییرات در طول زمان میتواند منجر به کاهش کیفیت و کمیت عملکرد شود. زیرا دادههای جدید از مجموعه دادههای آموزشی اصلی جا به جا میشود. آموزش منظم انسانی، بررسی های اجماع و دستورالعملهای برچسبگذاری به روز برای جلوگیری از جابهجایی برچسب مهم است.
حریم خصوصی: اطلاعات قابل شناسایی شخصی(PII) یا دادههای محرمانه به فرآیندهای برچسبگذاری دادههای ایمن نیاز دارد. روشهایی مانند ویرایش دادهها، ناشناسسازی و دادههای مصنوعی میتواند خطرات حریم خصوصی در برچسب را مدیریت کند.
هیچ راهحل یکسانی برای برچسبگذاری دادهها در مقیاس بزرگ وجود ندارد. برای برچسبگذاری موثر نیاز به برنامهریزی دقیق و متعادل با در نظر گرفتن عوامل مختلف وجود دارد.

پیشرفت روزافزون حوزه هوش مصنوعی و ML نیاز فزاینده به مجموعه دادههای برچسبدار با کیفیت بالا را ایجاد کرده است. در ادامه به معرفی و توضیح برخی از عناوین محوری میپردازیم:
اندازه و پیچیدگی: با پیشرفت قابلیتهای ML، مجموعه دادههایی که بر اساس آنها مدلها طراحی و آموزش داده میشود، بزرگتر و پیچیدهتر میشود.
اتوماسیون: استفاده از روش برچسبگذاری خودکار به طور چشمگیری در حال افزایش است و این نوع، هزینههای مربوط به برچسبگذاری دستی را کاهش داده است. حاشیه نویسی پیشبینی کننده، یادگیری انتقال و برچسبگذاری بدون کد همگی جزو عوامل کاهش دهنده حضور و نیروی انسانی است.
کیفیت: به دلیل کاربرد و استفاده از ML در زمینههای مهمی چون تشخیص پزشکی، وسایل نقلیه خودران و سایر سیستمهایی که ممکن است سلامتی انسان را تحت تاثیر قرار دهد اعمال میشود، کنترل کیفیت ضرورت مییابد.
همانطور که اندازه، پیچیدگی و بحرانی بودن مجموعه دادههای برچسبگذاری شده افزایش مییابد، نیاز به بهبود روشهایی که در حال حاضر برچسبگذاری و کیفیت را بررسی میکنیم نیز بیشتر میشود.
درک و انتخاب بهترین رویکرد برای یک پروژه برچسبگذاری دادهها میتواند تاثیر زیادی بر موفقیت از منظر مالی و کیفی داشته باشد. برخی از این بینشهای عملی عبارت است از:
ارزیابی دادهها: پیش از اتخاذ هرگونه رویکردی برای برچسبگذاری، پیچیدگی، حجم و نوع دادههایی را که قرار است با آنها کار کنید شناسایی کنید. از یک رویکرد روشمند استفاده کنید که به بهترین صورت با نیازهای خاص، بودجه و جدول زمانی مطابقت داشته باشد.
تضمین کیفیت: کیفیت را در اولویت قرار دهید. بررسیهای کیفی کاملی را انجام دهید به ویژه اگر از روشهای برچسبگذاری خودکار یا جمع سپاری استفاده میشود.
حفظ حریم خصوصی: اگر با افراد حساس یا PII سر و کار دارید، اقدامات محتاطانهای برای جلوگیری از هرگونه مشکل اخلاقی یا قانونی انجام دهید. ناشناسسازی و ویراش دادهها میتواند به حفظ حریم خصوصی کمک کند.
روشمند بودن: اجرای دستورالعمل ها و رویه های دقیق در راستای به حداقل رساندن سوگیری، ناسازگاری ها و اشتباهات کمک میکند. ابزارهای مستندسازی مبتنی بر هوش مصنوعی میتواند به پیشبرد تصمیمها و حفظ اطلاعات در دسترس آسان کمک کنند.
استفاده از راهحلهای موجود: در صورت ممکن، از مجموعه دادههای از پیش برچسبگذاری شده یا خدمات برچسبگذاری شده حرفهای استفاده کنید. این رویکرد میتوان سبب صرفهجویی در زمان و منابع شود. راهحلهایی مانند زمانبندی مبتنی بر هوش مصنوعی میتواند به بهینهسازی فرآیند کاری و تخصیص وظایف کمک کند.
برنامهریزی برای مقیاس پذیری: باید مراحل برچسبگذاری دادهها با روند عملیات و پروژههای در حال اجرا هماهنگ و متناسب باشد. سرمایهگذاری بر راهحلهای مقیاس پذیر از ابتدای کار در دراز مدت باعث صرفهجویی در هزینهها و منابع و همچنین جلوگیری از اتلاف و هددرفت تلاش نیروی انسانی میشود.
مطلع باشید: از فناوریهای نوظهور و جدید در این حیطه باخبر باشید. ابزارهایی مانند حاشیه نویسی پیشبینیکننده، برچسبگذاری بدون کد و همچنین دادههای مصنوعی که به صورت مستمر در حال تغییر و توسعه است، در کاهش هزینه و افزایش سرعت فرآیند برچسبگذاری دادهها موثر است.
برنامهریزی کامل و در نظر گرفتن این بینشها، در طراحی و توسعه عملیاتی موثر، سریع و با حداقل هزینهها نقش بسزایی دارد.
ادغام هوش مصنوعی و ML در هر جنبهای از جامعه به خوبی در حال انجام است و مجموعه دادههای مورد نیاز برای آموزش الگوریتمها همچنان با اندازه بسیار و پیچیدگی در حال رشد است. برای حفظ کیفیت و مقرون به صرفه بودن نسبی برچسبگذاری دادهها، نوآوری مستمر برای تکنیکهای موجود و نوظهور مورد نیاز است. استفاده از یک رویکرد موثر و متفکرانه و روشهایی برای برچسبگذاری دادهها برای پروژه ML اهمیت قابل توجهی دارد. با انتخاب روش برچسبگذاری مناسب برای نیازهای خود، میتوانید اطمینان حاصل کنید که پروژه مطابق با الزامات و بودجه در حال انجام است. درک تفاوتهای ظریف برچسبگذاری دادهها و پذیرش آخرین پیشرفتها به اطمینان از موفقیت پروژههای فعلی و همچنین پروژههای برچسبگذاری در آینده کمک میکند.
منبع: venturebeat







