


بنیانگذاران جوان قاعده کسبوکار استارتآپی را تغییر دادند؛ سن کمتر و توقع رشد بیشتر
بنیانگذاران استارتآپها امروز بدون سابقه کار در گوگل و متا، میلیونها دلار سرمایه جذب میکنند؛…
۱۰ مرداد ۱۴۰۵






۲۲ آذر ۱۴۰۴
زمان مطالعه : ۷ دقیقه

شرکت اوپنایآی که به تازگی پس از عرضه مدل جمینای ۳ از گوگل تحت فشار کمسابقه رقابتی قرار داشت حالا بهصورت رسمی از GPT-5.2 خود رونمایی کرده است که طبق اطلاعات منتشر شده در پست وبلاگی شرکت، پیشرفتهترین سری از مدلهای زبانی این شرکت برای «کار دانشی» است و میتواند پروژههای پیچیده و چندمرحلهای را با قدرت بیشتری به اجرا بگذارد.
به گزارش پیوست، اوپنایآی اعلام کرده است که GPT-5.2 نهتنها نسبت به نسل قبلی پیشرفت چشمگیری در دقت و توان استدلال داشته است، بلکه از نظر سرعت، مقیاسپذیری و صرفه اقتصادی نیز عملکرد بهتری نسبت به نسل قبلی خود دارد.
اوپنایآی میگوید کاربران سازمانی ChatGPT پیش از این بهطور متوسط روزانه بین ۴۰ تا ۶۰ دقیقه در زمان خود صرفهجویی کردهاند و کاربران سنگین حتی بیش از ۱۰ ساعت در هفته صرفهجویی زمان داشتهاند.
در نتیجه هدف شرکت از طراحی GPT-5.2، افزایش همین ارزش اقتصادی در مقیاسی بزرگتر است. با این حال گفتنی است که در حوزه هوش مصنوعی سازمانی شرکت انتروپیک، رقیب اوپنایآی، در حال حاضر دست بالا را دارد و با تمرکز بیشتر بر این بخش به جای عرضه مدلهای سنگین مولد تصویر و ویدیو به دنبال سلطه بر این بخش است.
با این حال اوپنایآی میگوید مدل جدید شرکت میتواند در ساخت فایلهای اکسل و ارائههای حرفهای، کدنویسی، تحلیل تصاویر، کار با اسناد بسیار طولانی، استفاده از ابزارها و مدیریت پروژههای پیچیده با کیفیتی نزدیک یا حتی بالاتر از نیروی انسانی برای سازمانها ایفای نقش کند.
یکی از مهمترین نکات معرفی GPT-5.2، عملکرد آن در ارزیابی GDPval است؛ بنچمارکی که توانایی مدلها را در انجام وظایف واقعی کار دانشی در ۴۴ شغل مختلف را مورد سنجش قرار میدهد.
بر اساس دادههای اوپنایآی، نسخه GPT-5.2 Thinking این شرکت در ۷۰.۹ درصد موارد توانسته عملکردی بهتر یا همسطح متخصصان متخصصان انسانی ارائه دهد. این نخستین بار است که اوپنایآی میگوید مدل زبانی بهطور میانگین در چنین طیف وسیعی از وظایف حرفهای، به سطح یا بالاتر از انسان رسیده است.
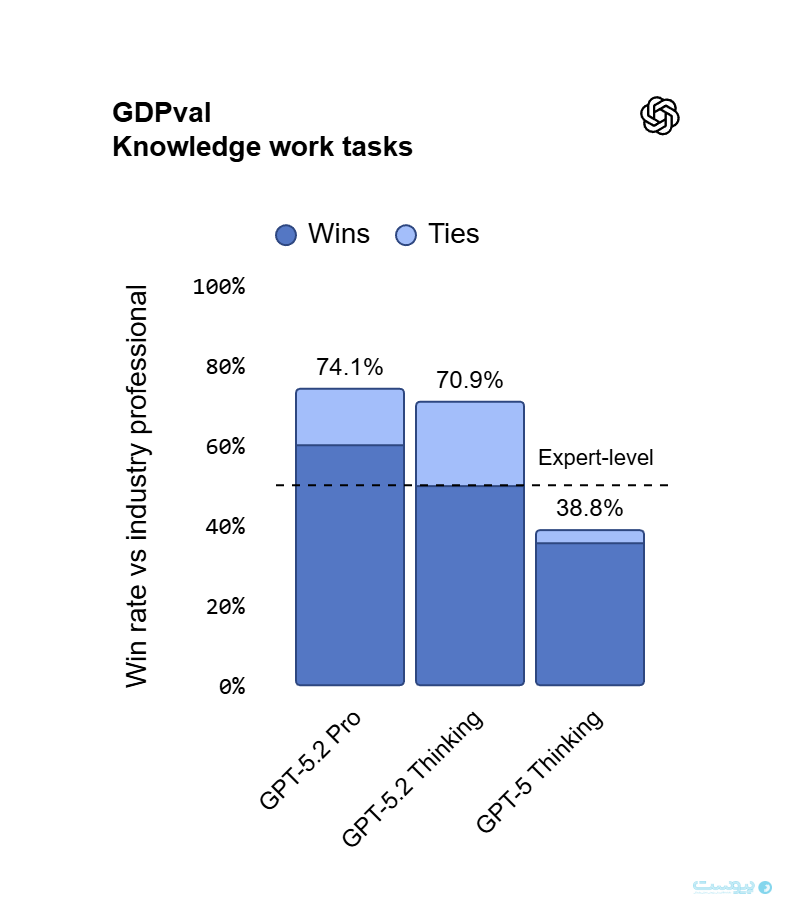
وظایفی که در این بخش به آنها اشاره شده موضوعاتی چون تهیه گزارشهای تحلیلی، ساخت ارائه، طراحی فایلهای اکسل و ارائه خروجیهایی است که معمولا توسط تیمهای حرفهای انجام میشود؛ مسالهای که میتواند به کاهش تقاضا برای نیروی کار جدید یا حتی تعدیل گسترده در این بخشها منجر شود و این نگرانی مدتها است به عنوان یکی از خطرات گسترش هوش مصنوعی شناخته میشود.
با این حال اوپنایآی بر نظارت انسانی در این بخش تاکید دارد و میگوید GPT-5.2 این خروجیها را با سرعتی بیش از ۱۱ برابر و با هزینهای کمتر از یک درصد نیروی انسانی تولید میکند اما به شرط اینکه همچنان نظارت انسانی برای استفادههای حساس حفظ شود.
براساس ارزیابیهای داخلی اوپنایآی GPT-5.2 در شبیهسازی وظایف تحلیلگران جوان بانکداری سرمایهگذاری، مانند ساخت مدلهای مالی سهصورتـی یا مدلهای LBO، امتیاز بهمراتب بالاتری نسبت به GPT-5.1 کسب کرده است. به گفته داوران، خروجیهای این مدل از نظر ساختار، قالببندی و سطح حرفهای بودن، به محصولات یک شرکت تخصصی شباهت دارد.
مدل GPT-5.2 Thinking در حوزه مهندسی نرمافزار نیز رکوردهای جدیدی را به ثبت رسانده است. این مدل در آزمون SWE-Bench Pro، که یکی از سختگیرانهترین ارزیابیهای مهندسی نرمافزار واقعی محسوب میشود، به امتیاز ۵۵.۶ درصد دست یافته و در نسخه Verified این آزمون امتیاز ۸۰ درصد را دارد.
در واقع این نتایج نشان میدهد GPT-5.2 میتواند با اطمینان بیشتری کدهای تولیدی را دیباگ کند، درخواستهای توسعه را پیادهسازی و حتی با حداقل دخالت انسانی، اصلاحات را تا مرحله نهایی پیگیری کند.
اولین تسترهای این مدل نیز اعلام کردهاند که GPT-5.2 در توسعه فرانتاند و طراحی رابطهای کاربری پیچیده، از جمله پروژههای سهبعدی و غیرمتعارف، عملکردی بهمراتب بهتر از نسل قبل دارد؛ موضوعی که آن را به یک ابزار روزمره قدرتمند برای توسعهدهندگان فولاستک تبدیل میکند.
بخش کدنویسی و توسعه نرمافزار نیز یکی دیگر از حوزههای تمرکز شرکت انتروپیک است که در حال حاضر بخش زیادی از کاربران آن را به خود اختصاص داده و شرکت اوپنایآی با وجود سلطه بر بخش کاربران عمومی، در رقابت با مدلهای انتروپیک در این حوزه با چالش مواجه است.
اوپنایآی همچنین اعلام کرده که GPT-5.2 نسبت به GPT-5.1 خطاهای ساختگی یا «هذیانگویی» های کمتری دارد و همین مساله اعتبار و اطمینان پذیری مدل را افزایش میدهد.
توهم یا هذیانگویی در واقع حالتی است که مدل اطلاعات نادرست را در قالبی باور پذیر و به عنوان اطلاعات حقیقی در اختیار کاربر میگذارد و در کاربردهای حساس میتواند دردسرساز باشد.
بر اساس دادههای داخلی شرکت، پاسخهای اشتباه در این مدل حدود ۳۰ درصد نسبت به نسل قبلی کاهش یافته است. این مساله به ویزه برای کاربران حرفهای حوزههای تحقیق، تحلیل، تصمیمسازی و نگارش تخصصی، از اهمیت بالا برخوردار است اما اوپنایآی تاکید دارد که همچنان بررسی انسانی در حوزههای تخصصی از اهمیت بالایی برخوردار است.
یکی از برجستهترین ویژگیهای GPT-5.2 که میتواند بخش کاربران عمومی را تحت تاثیر قرار دهد، توانایی این مدل در پردازش و کار با متنهای بسیار طولانی است (یکی از محدودیتهای مدلهای پیشین اوپنایآی در مقایسه با مدلهای شرکت گوگل.)
این مدل در ارزیابی MRCRv2، که توانایی استدلال در اسناد حجیم را میسنجد، به عملکردی نزدیک به ۱۰۰ درصد دقت در سناریوهای پیچیده دست یافته است. این به معنای آن است GPT-5.2 میتواند گزارشها، قراردادها، مقالات علمی، رونوشت جلسات و پروژههای چندفایلی را در مقیاس صدها هزار توکن با انسجام و دقت بالا تحلیل کند.
اوپنایآی میگوید این قابلیت یک مزیت کلیدی برای تحلیلهای عمیق، تلفیق منابع متعدد و پروژههای طولانیمدت است و بهویژه در زمانی که مدل با ابزارهای جدید API و پاسخهای فشرده ترکیب میشود از اهمیت ویژه برخودار است.
در بخش دید ماشینی نیز پست اوپنایآی نشان میدهد که GPT-5.2 پیشرفت قابلتوجهی نسبت به نسل قبل دارد.
براساس اطلاعات منتشر شده نرخ خطا در تحلیل نمودارها و رابطهای نرمافزاری در این نسل به حدود نصف کاهش یافته و مدل در درک چیدمان فضایی عناصر تصویر عملکرد دقیقتری دارد.
این قابلیت برای تحلیل داشبوردهای مالی، تصاویر فنی، نمودارهای مهندسی و اسکرینشاتهای نرمافزاری اهمیت ویژهای دارد و دامنه کاربرد GPT-5.2 را در حوزههایی مانند عملیات، مهندسی، طراحی و پشتیبانی مشتری گسترش میدهد.
علاوه بر این اوپنایآی میگوید که مدل GPT-5.2 Thinking از لحاظ استفاده از ابزارها به رکورد جدیدی رسیده و در آزمون Tau2-bench Telecom امتیاز ۹۸.۷ درصد را کسب کرده است.
این امتیاز بالا به معنای هماهنگی بهتر مدل در انجام وظایف چندمرحلهای، استفاده از APIها، جمعآوری داده از سیستمهای مختلف و تولید خروجی نهایی بدون گسست در فرآیند است؛ قابلیتی که برای خودکارسازی روندهای کاری سازمانی اهمیت حیاتی دارد.
اوپنایآی میگوید GPT-5.2 Pro و Thinking اکنون از بهترین ابزارهای کمکی برای پژوهشگران علمی محسوب میشوند. این مدلها در بنچمارکهای پیشرفتهای مانند GPQA Diamond و FrontierMath به رکوردهای جدیدی دست پیدا کردهاند و حتی در برخی پروژههای واقعی، پیشنهادهای ریاضی را ارائه کردهاند که پس از بررسی انسانی، معتبر تشخیص داده شده. در آزمونهای ARC-AGI نیز GPT-5.2 رکوردهای تازهای را در استدلال انتزاعی و حل نوآورانه مسائل به ثبت رسانده است.
طبق اعلام اوپنایآی نسخههای GPT-5.2 Instant، Thinking و Pro از امروز به شکل تدریجی در اختیار کاربران پولی ChatGPT قرار میگیرند و همزمان در API نیز برای توسعهدهندگان قابل دسترسی هستند.






