


بنیانگذاران جوان قاعده کسبوکار استارتآپی را تغییر دادند؛ سن کمتر و توقع رشد بیشتر
بنیانگذاران استارتآپها امروز بدون سابقه کار در گوگل و متا، میلیونها دلار سرمایه جذب میکنند؛…
۱۰ مرداد ۱۴۰۵






۲۹ مهر ۱۴۰۴
زمان مطالعه : ۶ دقیقه

شرکت آمازون مالک بزرگترین ارائه دهنده خدمات ابری جهان AWS (Amazon Web Services)، اعلام کرد که سیستمهای این شرکت عصر دوشنبه به حالت عادی بازگشته است. اختلال در زیرساخت ابری آمازون به اختلال سراسری اینترنت منجر شد و فعالیت هزاران وبسایت و برنامه محبوب از جمله اسنپچت، ردیت، فیسبوک، کوینبیس و تعداد زیادی از بازیهای آنلاین را با مشکل مواجه کرد.
به گزارش پیوست، آمازون طی بیانیهای از بازگشت خدمات خود به حالت عادی خبر داد و گفت «تمام سرویسهای AWS به عملیات عادی بازگشتهاند» این اختلال، که از مرکز داده معروف «US-EAST-1» در ویرجینیا سرچشمه گرفته بود، کاربران سراسر جهان را از لندن تا توکیو تحت تاثیر قرار داد و انجام بسیاری از فعالیتهای روزمره مانند پرداختهای آنلاین و تغییر بلیتهای هواپیمایی شد.
دلیل اصلی قطعی گسترده آمازون وب سرویسز طبق گزارشی از تککابال و دیگر منابع خبری، خطایی در سامانه نام دامنه یا همان DNS بود که سرویس پایگاهداده DynamoDB را مختل کرد. این حادثه در مرکز دادهی US-EAST-1، واقع در ایالت ویرجینیا، رخ داد؛ مرکزی که قدیمیترین و پرترافیکترین منطقه در شبکه AWS محسوب میشود و حدود ۳۵ تا ۴۰ درصد از کل ترافیک جهانی آمازون را مدیریت میکند.
ماجرا اندکی پس از نیمهشب به وقت اقیانوس آرام آغاز شد و از ساعت ۳:۱۱ بامداد به وقت شرق آمریکا، کاربران شروع به گزارش کندی پاسخها و خطاهای متعدد در خدمات متصل به AWS کردند. در همان لحظات اولیه مشخص شد که ریشه این مشکل به منطقه US-EAST-1 مربوط است. از آنجا که بسیاری از سرویسهای حیاتی آمازون و هزاران شرکت دیگر در سراسر جهان برای عملکرد خود به این منطقه وابستهاند، نقصی که در ابتدا محدود به نظر میرسید بهسرعت به بحرانی جهانی تبدیل شد.
کارشناسان فنی آمازون ظرف دو ساعت نخست شروع به اعمال اصلاحات کردند و تا حدود ساعت ۵:۲۷ صبح به وقت شرق آمریکا بیشتر درخواستها دوباره به حالت پردازش بازگشتند. با این حال، مشکل اصلی DNS تا ساعت ۳:۳۵ صبح به وقت اقیانوس آرام (۱۱:۳۵ صبح به وقت بریتانیا) هنوز بهطور کامل رفع نشده بود و برخی از سرویسها برای چند ساعت بعد از آن همچنان با تاخیر و مشکل در پردازش پیامها روبهرو بودند. بررسیهای داخلی نشان داد که علت اصلی این اختلال، خرابی در سامانه DNS مرتبط با پایگاهداده DynamoDB است. زمانی که این سامانه از کار افتاد، نرمافزارها نتوانستند آدرس درست پایگاهداده را پیدا کنند و در نتیجه ارتباطشان با دادههای ذخیرهشده قطع شد. کارشناسان امنیتی نیز اعلام کردند که این حادثه ناشی از یک نقص فنی در تنظیمات DNS یا BGP بوده و هیچ نشانهای از حمله سایبری وجود ندارد.
طبق دادههای Downdetector و Ookla، در طول چند ساعت بیش از ۴ میلیون گزارش کاربری درباره اختلال در دسترسی به سرویسها به ثبت رسید. این رویداد از نظر گستردگی، بزرگترین اختلال اینترنتی پس از حادثه CrowdStrike بود که بیمارستانها، بانکها و فرودگاهها را فلج کرد.
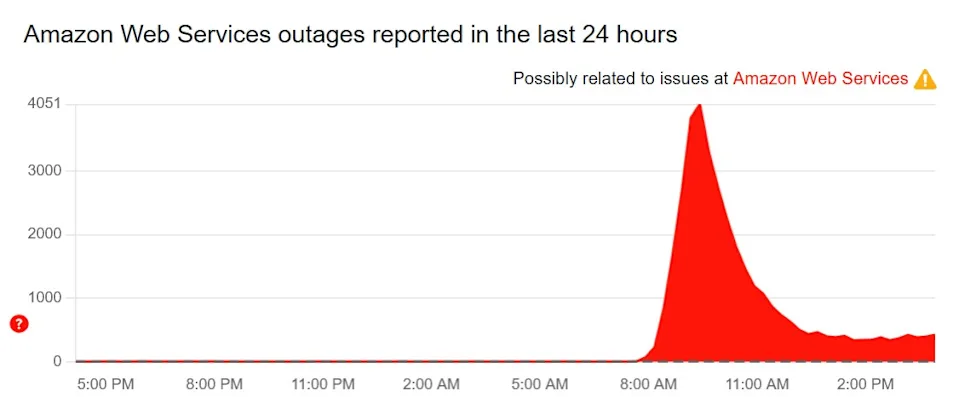
با گسترش خطا در سیستمهای آمازون، سایر بخشهای زیرساختی آمازون تحت تاثیر قرار گرفتند. سرویسهایی مانند EC2 که مسئول پردازش ابری در لحظه است، IAM، که مدیریت هویت و دسترسی کاربران را بر عهده دارد و DynamoDB Global Tables، که برای هماهنگی پایگاهدادهها در سراسر جهان استفاده میشود، همگی دچار مشکل شدند.
از آنجا که بسیاری از برنامهها و حتی مواردی که در خارج از آمریکا میزبانی میشون به نقاط پایانی منطقه US-EAST-1 متکی هستند، دامنهی اختلال از مرزهای ایالات متحده فراتر رفت و کاربران در اروپا، آسیا و آمریکای لاتین نیز با مشکلات مشابه روبهرو شدند. این حادثه نشان داد که صرف استفاده از چند منطقهی دسترسپذیر برای ایجاد پایداری کافی نیست؛ زیرا اگر لایه DNS و شبکهی اصلی منطقهای دچار نقص شود، حتی وجود سختافزارهای پشتیبان نیز نمیتواند از گسترش اختلال جلوگیری کند.
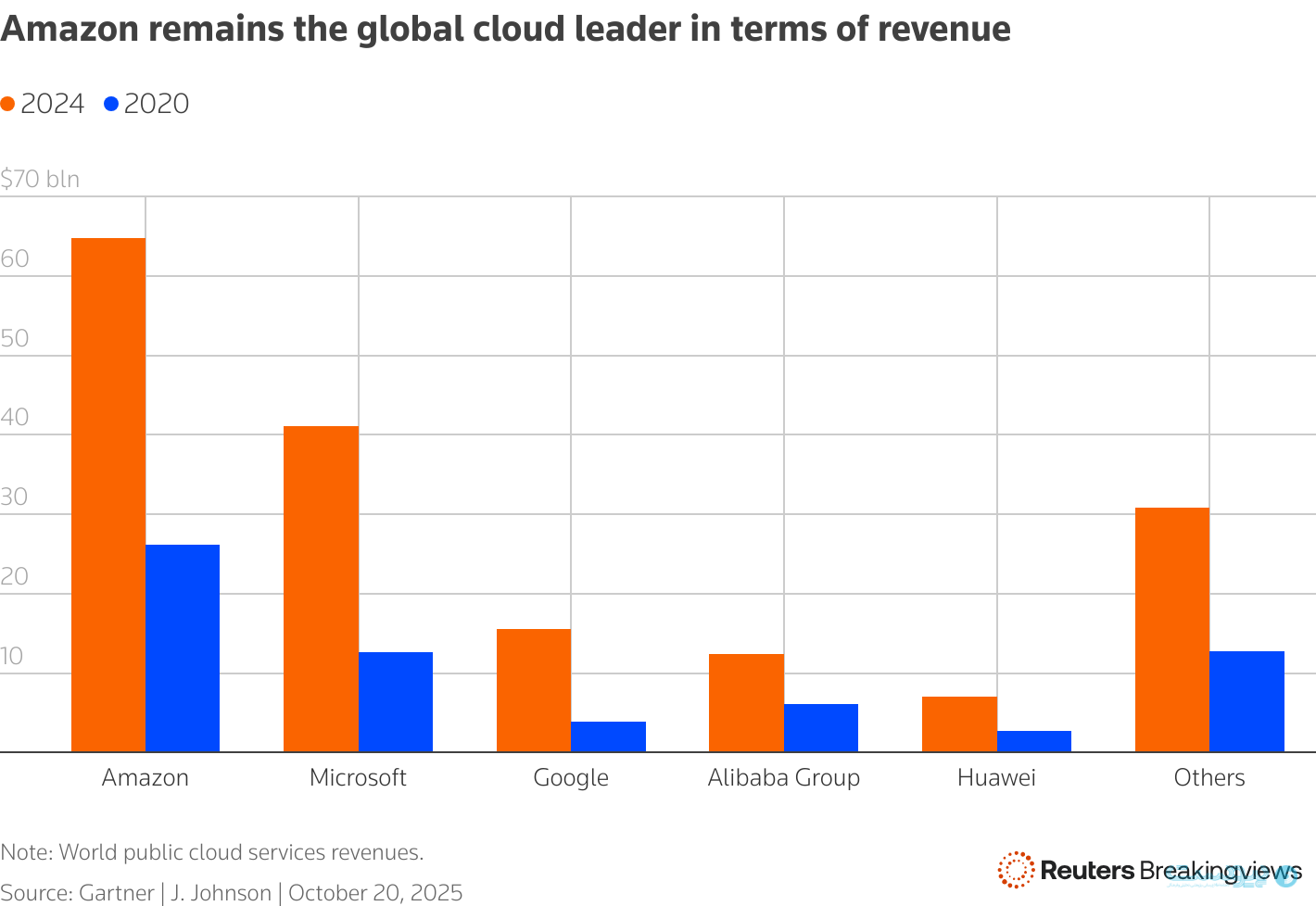
از آنجایی که براساس آخرین دادهها شرکت آمازون همچنان بزرگترین ارائه دهنده ابری جهان است، این رویداد تاثیر گستردهای بر صنایع مختلف جهان گذاشت.
در بخش خدمات مالی، پلتفرمهایی مانند Coinbase، Robinhood، Venmo و Chime برای چند ساعت از دسترس خارج شدند و تراکنشهای کاربران متوقف شد. در بریتانیا نیز بانکهای Lloyds، Halifax و Bank of Scotland با مشکل در پرداختها و عملیات روزانه مواجه شدند. در بخش زیرساختهای حیاتی، وبسایت اداره مالیات و گمرک بریتانیا (HMRC) از کار افتاد و شرکتهای هواپیمایی بزرگ مانند Delta و United در رزرو و تغییر بلیتها دچار اختلال شدند. همچنین بسیاری از ابزارهای تجاری پرکاربرد نظیر Slack، Zoom و Jira ناپایدار شدند و فعالیت هزاران شرکت و کاربر را در سراسر جهان مختل کردند.
تأثیر این قطعی تنها به حوزهی کاری و اقتصادی محدود نماند و کاربران عادی نیز تاثیر آن را مستقیما احساس کردند. سرویسهای آمازون از جمله وبسایت خرید Amazon.com، سرویس پخش Prime Video و Amazon Music برای مدتی از دتسرس خارج شدند. دستگاههای خانگی هوشمند مانند دوربینهای Ring و دستیار صوتی Alexa پاسخگو نبودند. شبکههای اجتماعی و پلتفرمهای سرگرمی همچون یوتیوب، تیندر، اکسباکس، اسنپچت ، Canva، Roblox، بازی فورتنایت و PlayStation Network نیز در مقاطع مختلف دچار قطعی شدند و میلیونها کاربر امکان دسترسی به حسابهای خود را از دست دادند.

مرکز داده US-EAST-1 یکی از قدیمیترین و بزرگترین مراکز AWS است، پیشتر نیز در سالهای ۲۰۲۰ و ۲۰۲۱ نیز دچار قطعیهای مشابهی شده بود.
کارشناسان میگویند این تکرار، ضرورت بازنگری در زیرساخت این مرکز را نشان میدهد.کن بیرمن، استاد علوم کامپیوتر دانشگاه کرنل، در این باره به رویترز گفت: «توسعهدهندگان باید تحمل خطای سیستمهای خود را تقویت کنند.آمازون وب سرویسز ابزارهای لازم برای ایجاد پشتیبان را فراهم کرده، اما بسیاری از شرکتها برای کاهش هزینهها از این قابلیتها صرفنظر میکنند و در زمان بحران آسیبپذیر میشوند.»
کارشناسان این حادثه را همچنین نشانهای از آسیبپذیری زیرساختهای دیجیتال جهانی میدانند. جیک مور، مشاور امنیت سایبری شرکت اروپایی ESET، در این باره گفت «این حادثه بار دیگر وابستگی خطرناک ما به زیرساختهای شکننده و معدود ارائهدهندگان بزرگ ابری را آشکار کرد.»
نیشانت ساستری، مدیر پژوهش در دانشگاه سوری بریتانیا نیز افزود: «دلیل اصلی این بحران آن است که بسیاری از شرکتهای بزرگ تنها به یک سرویس ابری متکیاند.»
به گفته رایان گریفین، مدیر بخش سایبری شرکت بیمه McGill and Partners، ساعات ازکارافتادگی خدمات ابری ممکن است به زیانهای میلیونها دلاری برای شرکتها منتهی شود.






