


بنیانگذاران جوان قاعده کسبوکار استارتآپی را تغییر دادند؛ سن کمتر و توقع رشد بیشتر
بنیانگذاران استارتآپها امروز بدون سابقه کار در گوگل و متا، میلیونها دلار سرمایه جذب میکنند؛…
۱۰ مرداد ۱۴۰۵






۱۶ بهمن ۱۴۰۳
زمان مطالعه : ۵ دقیقه

گزارشی از فایننشال تایمز میگوید شرکت هوش مصنوعی انتروپیک، استارتآپ تحت حمایت گوگل و آمازون، ترفند جدیدی را برای جلوگیری از تولید محتوای خطرناک در مدلهای خود توسعه داده است. تولید محتوای مخرب و جیلبریک یا دور زدن محدودیتها یکی از چالشهای امروز شرکتهای فعال در حوزه هوش مصنوعی و انتروپیک به عنوان یکی از پیشتازان حوزه امنیت هوش مصنوعی تمرکز ویژهای بر این بخش دارد.
به گزارش پیوست، این سیستم که به گفته انتروپیک براساس آزمون اولیه روی هوش مصنوعی این شرکت تا حدود ۹۵ درصد از تلاشهای مخرب را جلوگیری میکند، یکی از نگرانیهای مهم در سیستمهای امنیتی یا افزایش تعداد رد درخواستهای صحیح را نیز تا حد زیادی برطرف کرده است. با این حال استفاده از سیستم انتروپیک هزینه اجرای مدلهای هوش مصنوعی را افزایش میدهد.
سیستم جدیدی که انتروپیک در مقاله جدید خود توصیف کرده است «constitutional classifiers» یا دستهبندیکنندههای اساسی نام دارد. این سیستم در واقع یک مدل هوش مصنوعی است که به عنوان لایه محافظی برروی مدلهای بزرگ زبانی قرار میگیرد. این مدل با قرار گرفتن روی مدلهای بزرگ زبانی از جمله مدل انتروپیک برای چتبات Claude، ورودی و خروجیهای را از لحاظ محتوای خطرناک بررسی و کنترل میکند.
سیستم ساخته انتروپیک که در حال حاضر برای جذب ۲ میلیارد دلار با ارزشگذاری ۶۰ میلیارد دلاری تلاش میکند، در حالی معرفی شده است که فعالان این صنعت با نگرانی «جیلبریک» یا دو زدن محدودیتهای هوش مصنوعی دست و پنجه نرم میکنند و هرکدام به طریقی برای جلوگیری از آن تلاش کردهاند اما همچنان راهحلی نهایی برای این مساله شاهد نیستیم.
تبهکاران با استفاده از ترفندهای جیلبریک در واقع محدودیتهای هوش مصنوعی را کنار میزنند و مدل را وادار به تولید محتوای غیرقانونی یا اطلاعات خطرناکی میکنند که علاوه بر تبعات فیزیکی یا سایبری، ممکن است مسئولیتهایی را برای شرکت ارائه دهنده هوش مصنوعی به دنبال داشته باشد.
البته که انتروپیک در تلاش برای مقابله با این مشکل تنها نیست و شرکتهای دیگر نیز رویکرد خاص خود را در پیش گرفتهاند تا از خشم احتمالی رگولاتورها در امان باشند. فایننشال تایمز میگوید شرکت مایکروسافت ماه مارس سال گذشته از سیستم «Prompt Shields» یا محافظهای پرامپت رونامیی کرد و شرکت متا هم از یک مدل محافظ پرامپت در ماه جولای سال گذشته رونمایی کرد که البته پژوهشگران خیلی زود راهکارهایی را برای دور زدن محدودیتهای این سیستم یافتند و حالا آن نقاط ضعف برطرف شدهاند.
انتروپیک مدعی است که سیستم ساخته این شرکت به سرعت نسبت به تلاشهای نادرست پاسخ میدهد و با تغییرات وفق پیدا میکند. فایننشال تایمز به نقل از مارینانک شارما، یکی از اعضای فنی شرکت انتروپیک، میگوید: «انگیزه اصلی این کار مربوط به مسائل جدی [سلاح] شیمیایی بود [اما] مزیت اصلی این روش توانایی پاسخ و انطباق سریع آن است.»
انتروپیک از این سیستم فورا در مدلهای Claude استفاده نخواهد کرد اما استفاده از آن را برای مدلهای خطرناکتری که در آینده عرضه میشوند مد نظر دارد. شارما افزود: «بزرگترین برداشت از این اثر این است که ما فکر میکنیم این مساله قابل ردیابی است.»
راهحل پیشنهادی این استارتآپ براساس «اساسنامهای» از قوانین ساخته شده است که مجاز و غیرمجاز را تعریف میکنند و این مقررات را میتوان برای شناسایی محتوای مختلف منطبق کرد.
برخی از انواع جیلبریک یا تلاش برای دور زدن محدودیتها شناخته شده هستند که برای مثال میتوان به بزرگنویسی عجیب در پرامپت یا درخواست برای ایفای نقش هوش مصنوعی اشاره کرد که در میان یک داستان نقش آفرینی درخواستی را که در غیر این صورت محدود است، پاسخ میدهد.
انتروپیک برای برای اطمینان از بازدهی این سیستم در یک سیستم باگ بونتی یا پاداش برای پیدا کردن نقایض تا سرحد ۱۵ هزار دلار به افرادی که از محدودیتهای امنیتی عبور کنند پاداش داده است. این افراد بیش از ۳ هزار ساعت برای عبور از محدودیتهای این سیستم تلاش کردند.
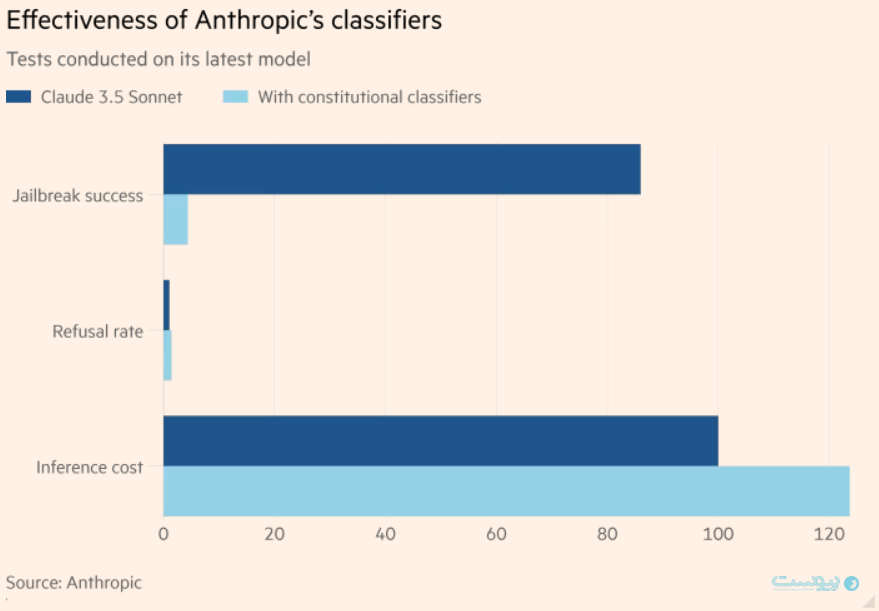
براساس دادههای شرکت انتروپیک، مدل هوش مصنوعی Claude 3.5 Sonnet توانست بیش از ۹۵ درصد از تلاشها را با استفاده از دستهبندیکنندهها رد کند. این در حالی است که بدون استفاده از این سیستم نرخ موفقیت به تنها ۱۴ درصد کاهش پیدا میکند.
شرکتهای بزرگ فناوری در تلاشند تا به گونهای محدودیتها را اعمال کننده که از بازدهی مدلهای هوش مصنوعی کاسته نشود. تمهیدات امنیتی معمولا باعث میشوند تا مدلهای هوش مصنوعی بیش از حد محتاط شوند و درخواستهای صحیح را نیز رد کنند. برای مثال چنین پدیده ای را در اولین نسخههای مولد تصویر جمنا یا مدل Llama 2 از متا مشاهده کردیم. انتروپیک میگوید سیستم کلسیفایرها یا دستهبندیکنندههای این شرکت تنها «۰.۳۸ درصد» نرخ رد درخواست را افزایش داد.
با این حال چنین محافظتهایی با هزینه اضافی برای شرکتها همراه هستند و این در حالی است که فعالان این عرصه در حال حاضر هزینه هنگفتی را به آموزش و اجرای مدلهای خود اختصاص دادهاند. انتروپیک میگوید استفاده از این سیستم به افزایش ۲۴ درصدی بار مرحله استنتاج یا هزینه اجرای مدلهای منجر میشود.
متخصصان امنیتی معتقدند که دسترسی گسترده به سیستمهای هوش مصنوعی باعث شده تا افراد معمولی که پیشتر دانش انجام برخی از کارهای خطرناک را نداشتند، حالا امکان دسترسی ساده به این دانش را پیدا کنند.
رم شانکار سیوا کومار، رهبر تیم قرمز هوش مصنوعی در مایکروسافت، میگوید: «در سال ۲۰۱۶ فعال خطرناکی که ما در ذهنمان بود یک دشمن دولتی قدرتمند بود. امروز تقریبا تمام فعالان خطرناک ما یک نوجوان بددهن است.»






