
بنیانگذاران جوان قاعده کسبوکار استارتآپی را تغییر دادند؛ سن کمتر و توقع رشد بیشتر
بنیانگذاران استارتآپها امروز بدون سابقه کار در گوگل و متا، میلیونها دلار سرمایه جذب میکنند؛…
۱۰ مرداد ۱۴۰۵







مینا رضایی
۶ آبان ۱۴۰۲
زمان مطالعه : ۸ دقیقه

مدل زبانی بزرگ LLM ترجمه Large Language Model است. این مدلهای زبانی از شبکههای عصبی مصنوعی با تعداد زیادی پارامتر استفاده میکنند که بر اساس مجموعه دادههای عظیم متن از منابع مختلف، مانند کتابها، مقالات، وبسایتها، بازخورد مشتریان، پستهای رسانههای اجتماعی و بررسی محصول آموزش دیدهاند.
به گزارش پیوست، آموزش این مدلها معمولا با استفاده از فناوریهایی مانند یادگیری ماشینی انجام و تقویت میشود. از مدلهای بزرگ زبانی میتوان به LLM GPT-3 که توسط OpenAI توسعه داده شده است، اشاره کرد. چت جیپیتی قادر به تولید متون طولانی، پاسخ به سوالات، ترجمه، توصیف تصاویر و انجام وظایف دیگر در زمینه پردازش زبان است. این مدلها به طور گسترده در برنامهها و سیستمهای هوش مصنوعی استفاده میشوند.
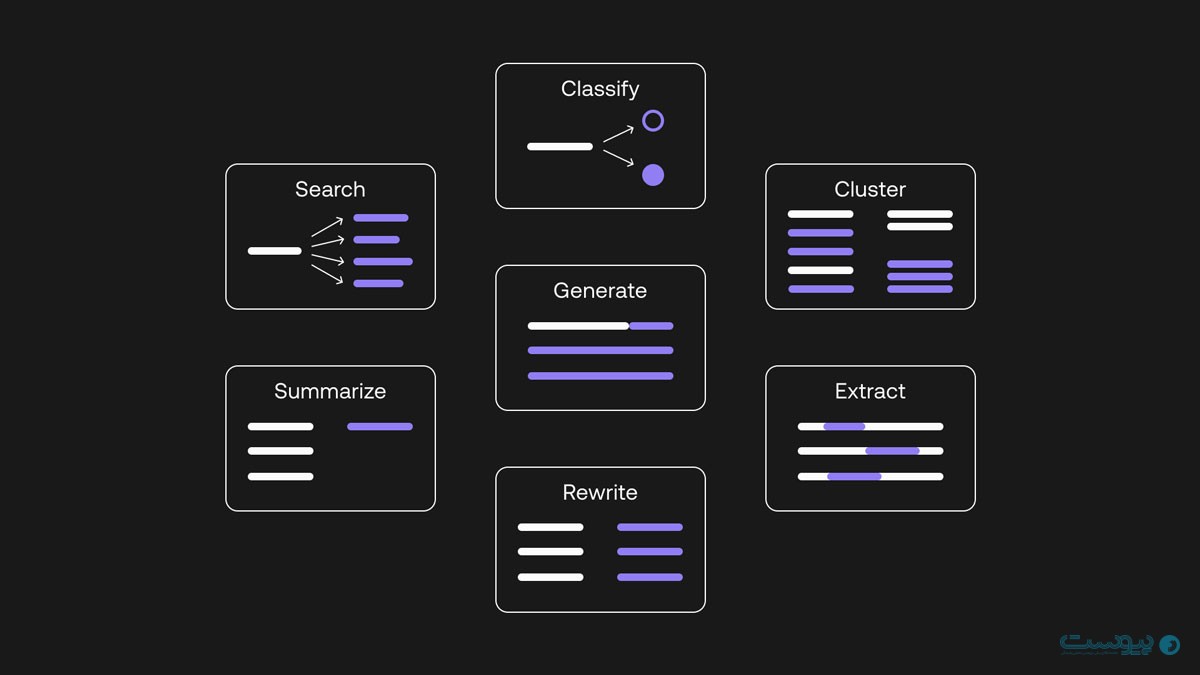
مدل زبانی LLM (Language Model) مخفف “Large Language Model” است که با استفاده از شبکههای عصبی، با تعداد بسیار زیادی پارامتر آموزش میبینند. مدل زبانی بزرگ LLM سیستمهای هوش مصنوعی پیشرفتهای هستند که کاربردهای بسیاری در این حوزه دارند که در ادامه به برخی از کاربردهای اصلی آنها اشاره میکنیم:
مدل زبانی LLM قادر به تولید متون بلند و متنوع است. این قابلیت میتواند در زمینههایی مانند نوشتن مقالات، شرح تصاویر، تولید متون خلاقانه و گزارشهای مختلف بهصورت خودکار مفید باشد.
از این زبان پیشرفته میتوان در پردازش زبان طبیعی مانند تشخیص احساسات و شخصیتها، ترجمه، خلاصهسازی متون و پاسخ به سوالات استفاده کرد.
قابلیتهای مدل زبانی LLM، در تجزیه و تحلیل دادهها و پیشبینیها مورد استفاده قرار میگیرد. بهطور مثال در تجزیه و تحلیل احساسات مختلف، پیشبینی روند بازار و پیشبینی رفتار کاربران و حتی بازار ارز دیجیتال نیز کاربرد دارد.
با استفاده از LLM بهعنوان زبانی قدرتمند، میتوان سیستمهای هوشمندی را طراحی کرد که قادر به درک و پاسخ به درخواستها و سوالات کاربران باشند. این مدلها میتوانند در ایجاد چتباتها و سیستمهای پاسخگویی خودکار به کاربران مورد استفاده قرار بگیرند.
مدل بزرگ زبانی LLM میتواند در زمینه تولید محتوا و خلاقیت نیز استفاده شود. بهطور مثال در تولید داستانها، شعرها، موسیقی و تولید طرحهای گرافیکی بر اساس دادههای گستردهای که دارد میتواند خلاقیت نیز ایجاد کند.
در این قسمت از مطلب به نمونههایی از مدلهای زبانی LLM اشاره میکنیم که در حوزه هوش مصنوعی بسیار قدرتمند ظاهر شدهاند.
این مدل توسط شرکت OpenAI توسعه داده شده است و تا کنون یکی از قدرتمندترین مدلهای LLM محسوب میشود. GPT-3 قادر است به سوالات پاسخ دهد و متنهایی ایجاد کند که دارای چندین پاراگراف هستند و در وظایف پردازش زبان طبیعی عملکرد خوبی دارند.

Bidirectional Encoder Representations from Transformers نیز یکی از مدلهای LLM پرکاربرد است که توسط گوگل توسعه داده شده است. این مدل برای پردازش احساسات، ترجمه ماشینی و پرسش و پاسخ بسیار مفید است.
این مدل نیز یک مدل LLM است که بر پایه ترانسفورمر توسعه داده شده است. XLNet دارای معماریای منحصر به فرد است که توانایی فهم روابط دو طرفه بین کلمات را دارد و در وظایف پردازش زبان مانند تشخیص شخصیتها و ترجمه ماشینی عملکرد خوبی دارد.
نمونه های مدلهای LLM معروف در زمینه هوش مصنوعی بسیار گسترده است و با توجه به رشد سریع در این حوزه، مدلهای جدیدتری نیز معرفی میشود.
مدلهای زبانی LLM ویژگیهای بسیاری دارند که در ادامه به چند مورد مهم از آنها اشاره خواهیم کرد:
۱- پیشآموزش: مدلهای LLM قبل از استفاده برای وظایف خاصی، آموزش داده میشوند و به این معنی است که این مدلها از متونی با حجم بالا، آمارهای زبانی را فرا گرفته و نمایشی عمومی از زبان را درک میکنند.
۲- توجه به ترتیب وابستگیها: مدلهای LLM توجه خاصی به ترتیب وابستگیهای کلمات در یک جمله یا متن دارند. درواقع مدلهای LLM میتوانند ارتباطات میان کلمات را بر اساس موقعیت آنها در جمله درک کنند و به نوعی ترتیب وابستگیها را در تولید متون خود رعایت کنند.
۳- نمایش آماری کلمات: مدلهای LLM کلمات را با استفاده از نمایش (vector representation) مدلسازی میکنند که با استفاده از تکنیکهایی مانند Word2Vec یا GloVe به دست میآید و ویژگیهای معنایی و زبانی کلمات را در خود جای میدهد.
۴- کاربرد در وظایف پردازش زبان: مدلهای LLM به خاطر قدرتی که دارند در درک و تولید متون، مورد استفاده قرار میگیرد که این شامل تشخیص احساسات، ترجمه ماشینی، پرسش و پاسخ، خلاصهسازی متون و سایر وظایف مشابه است.
۵- قابلیت تولید متون خلاقانه: یکی از ویژگیهای جذاب مدلهای LLM، توانایی تولید متون خلاقانه و غیرقابل پیشبینی است. این مدلها میتوانند متونی را با ساختار منطقی و زبانی صحیح تولید کرده و در برخی موارد حتی متونی با جنبههای خلاقانه تولید کنند.
شایان ذکر است که مدلهای LLM همچنان دارای محدودیتها و چالشهایی مانند درک دقیق مفهوم، حفظ ساختار منطقی و قضاوت اخلاقی است که برای بهبود این موضوع باید توجه و پیشرفتهای بیشتری در این زمینه صورت بگیرد.
عملکرد مدل زبان LLM بر اساس معماری و آموزشی که دریافت کرده، متفاوت است. اما در مجموع، این مدلها توانایی درک و تولید متون را دارند که بر اساس فرآیند آموزشی صورت میگیرد. عملکرد مدلهای LLM به شرح زیر است:
مدل زبانی بزرگ LLM از دادههایی استفاده میکنند که در آموزش و طراحی در دسترس آنها قرار داده شده و همانطور که اشاره کردیم, قادر هستند مفاهیم و روابط میان کلمات را درک کنند. با این اطلاعات، مدل زبانی LLM میتواند به سوالات کاربر پاسخ دهد، متون را تفسیر کند و در وظایف پردازش زبان مانند تشخیص احساسات یا ترجمه ماشینی عملکرد خوبی داشته باشد.
مدلهای LLM قادر به تولید متون جدید با توجه به الگوهای زبانی هستند. با استفاده از اطلاعات زبانی و آمارها که در فرآیند دادههای آموزشی مورد آموزش قرار گرفتهاند.
مدل زبانی بزرگ LLM توانایی درک ارتباطات میان کلمات را دارد. در واقع مفهوم و دستورات جملات را درک کرده و ارتباطات داخل جمله را در نظر میگیرد. بهعنوان مثال، اگر در یک جمله کلمه “گربه” آمده باشد و بعد از آن کلمه “خورد” بیاید، مدل میتواند درک کند که گربه فاعل است و خوردن را انجام میدهد.
زبان LLM میتواند با توجه به آموزشی که دریافت کرده است، با وظایف خاصی سازگار شود. بهعنوان مثال، با تمرین مدل با دادههای ترجمه، میتوانید آن را به عنوان یک مدل ترجمه ماشینی استفاده کنید.
فرایند آموزش LLM شامل چند مرحله است که در ادامه توضیحات بیشتری میدهیم:
ابتدا برای آموزش LLM باید یک مجموعه داده گستردهای جمعآوری شود. این مجموعه داده ممکن است شامل متون مختلفی مانند کتابها، مقالات، وبسایتها، نوشتارهای اینترنتی و غیره باشد و باید حاوی نمونههای متنی باشد که مدل بتواند از طریق آنها آموزش ببیند.
مرحله بعدی، پیشپردازش داده است. در این مرحله، متنهای جمعآوری شده تفکیک میشود و مانند تقسیم متن به جملات و کلمات، حذف علائم نگارشی، تبدیل حروف به کوچک است.
بعد از پیشپردازش داده، باید ساختار مدل تعیین شود و لازم به ذکر است که ساختار مدل بر اساس نیازها و منابع موجود تعیین میشود.
در این مرحله، مدل با استفاده از مجموعه دادهها، آموزش میبیند. آموزش مدل ممکن است مدت زمان طولانیای به طول بیانجامد و بسته به حجم داده و قدرت محاسباتی موجود متفاوت باشد.
بعد از آموزش، مدل باید ارزیابی شود. برای این کار، یک مجموعه داده ارزیابی جداگانه تهیه میشود که مدل روی آن قابل تست است. این مجموعه داده شامل نمونههایی است که جزو دادههای قبلی مدل نیست. ارزیابی مدل ممکن است شامل معیارهایی مانند دقت پیشبینی، کسر نمونههایی که مدل به درستی پیشبینی نکرده و سرعت اجرا باشد.
پس از ارزیابی، ممکن است نیاز به تنظیمات مدل باشد. هدف از تنظیم مدل بهبود عملکرد و دقت آن است. توجه داشته باشید که فرآیند آموزش مدل زبان بزرگ میتواند پیچیده و زمانبر بوده و نیاز به منابع قدرتمند محاسباتی داشته باشد. همچنین، موفقیت آموزش مدل بستگی به کیفیت و حجم مجموعه داده، ساختار مدل و پارامترهای آموزش دارد.
مدل بزرگ زبانی LLM به زودی تحولی بزرگ در صنعت هوش مصنوعی ایجاد میکند. با این حال، برای بهینهسازی LLM، توسعه دهندگان باید از دادههای گفتاری با کیفیتی بالا برای نتایج دقیق و طراحی مدلهای هوش مصنوعی استفاده کنند.
Shaip یکی از راهحلهای پیشرو در فناوری هوش مصنوعی است که طیف گستردهای از دادههای گفتاری را در بیش از ۵۰ زبان و فرمتهای مختلف ارائه میدهد.






