
بنیانگذاران جوان قاعده کسبوکار استارتآپی را تغییر دادند؛ سن کمتر و توقع رشد بیشتر
بنیانگذاران استارتآپها امروز بدون سابقه کار در گوگل و متا، میلیونها دلار سرمایه جذب میکنند؛…
۱۰ مرداد ۱۴۰۵







مونا میرزایی

۴ بهمن ۱۴۰۳
زمان مطالعه : ۹ دقیقه

همگام شدن با سرعت بالای پیشرفت هوش مصنوعی، به ویژه با وجود هوش مصنوعی مولد در خط مقدم، میتواند چالشبرانگیز باشد. هوش مصنوعی مولد که بسیاری از طریق ابزارهایی مانند ChatGPT با آن آشنا هستند، در حال شکستن مرزهای جدید است و نه تنها متن، بلکه تصاویر، صدا و ویدیو را نیز پردازش و تولید میکند. بررسی هوش مصنوعی مولد روند پیشرفت و تاثیر این فناوری برجنبههای مختلف را نشان میدهد.
هوش مصنوعی مولد که با تولید متن آغاز شد، اکنون به پردازش و ایجاد انواع مختلف دادهها مانند تصاویر، صدا و ویدیو تکامل یافته است. این توانایی پردازش همزمان چندین نوع داده و تولید خروجیهای مرتبط با هم، به عنوان هوش مصنوعی چندوجهی شناخته میشود.
هوش مصنوعی مولد دیگر محدود به تحلیل دادههای موجود نیست و صرفا به عنوان یک پردازشگر اطلاعات عمل نمیکند. این فناوری قادر است دادههای جدید و خلاقانه تولید کند. به عنوان مثال، اگر شما تصویری ساده را به یک هوش مصنوعی نشان دهید و از آن بخواهید یک پوستر تبلیغاتی حرفهای طراحی کند، این فناوری میتواند یک طرح چشمنواز و کاملاً متناسب با درخواست شما تولید کند.
شاید در چند سال اخیر، الگوریتمهای تولید محتوا توسط هوش مصنوعی اغلب به دلیل محدودیتهای فنی، تصاویر مصنوعی و غیر طبیعی تولید میکردند. اما با پیشرفتهای چشمگیر در حوزه یادگیری ماشین، این الگوریتمها اکنون قادرند محتوای تصویری، صوتی و حتی ویدیویی با کیفیت بسیار بالا و واقعگرایانه تولید کنند. از اینرو هوش مصنوعی به ابزاری قدرتمند برای خلق آثار هنری تبدیل شده است و یعنی با پیشرفتهای هوش مصنوعی مولد یک انقلاب واقعی در دنیای هنر و رسانه رخ میدهد.
از طرفی این تکامل چشمگیر یک شبه اتفاق نیفتاده است. برای اینکه هوش مصنوعی به درک و تواناییهای بیانگر انسانگونه دست یابد، به مقادیر عظیمی از داده و یک فرآیند آموزش پیچیده برای یادگیری کارآمد نیاز دارد.
این تصویر مربوط به صفحه هوش مصنوعی ساخت ویدئوی Sora است که محدودیت دسترسی به آن برای تمام کاربران اشتراک پرو پلاس ChatGPT میتوانند با IP غیراروپایی از آدرس Sora.com به این مدل دسترسی داشته باشند.
هوش مصنوعی مولد به سطح فعلی خود از طریق مجموعه دادههای عظیم و فرآیندهای آموزش پیچیده رسیده است. در میان اینها، پیشآموزش و پسآموزش عوامل کلیدی هستند که عملکرد مدلهای هوش مصنوعی را تعیین میکنند.
تصویری که ارائه شده است، نسبت منابع مختلف داده در دادههای پیشتمرین مدلهای زبانی بزرگ (LLMs) را نشان میدهد. این تصویر بهطور مؤثری ترکیب دادههایی را که برای آموزش این مدلهای قدرتمند هوش مصنوعی استفاده میشود، نشان میدهد.
بهطور کلی، این تصویر به تنوع گسترده منابع داده که برای آموزش مدلهای زبانی بزرگ ضروری است، اشاره دارد. با درک ترکیب این مجموعه دادهها، میتوان به نقاط قوت و محدودیتهای مدلهای مختلف پی برد.
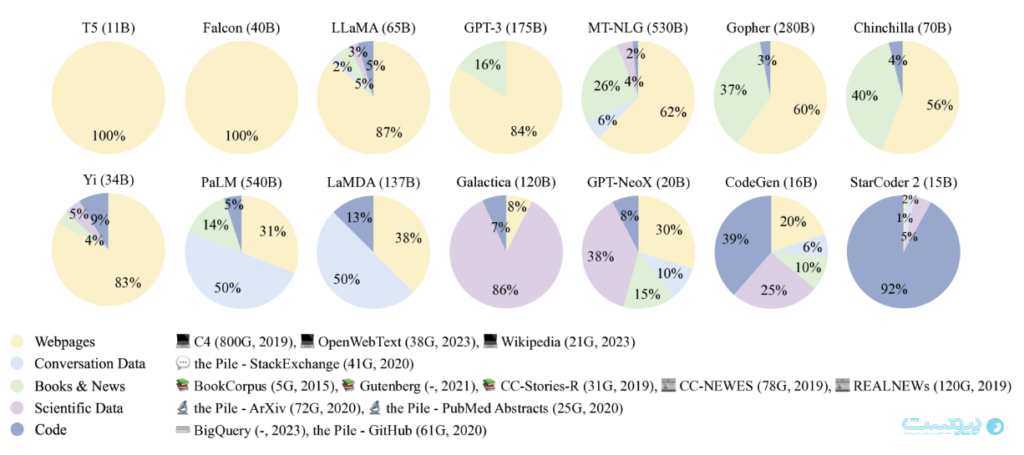
پیشآموزش مرحله اولیه یادگیری است که در آن یک مدل با مقادیر عظیمی از دادهها آموزش میبیند تا زبان و ساختارهای داده اساسی را درک کند. در طول این مرحله، از کورپوسهای بزرگ، مانند مقالات خبری، کتابها و محتوای وب برای آموزش مدل در مورد چگونگی پیشبینی کلمه بعدی یا درک زمینه استفاده میشود.
یکی از روشهای رایج پیشآموزش شامل پیشبینی کلمه بعدی در یک دنباله بر اساس زمینه است. به عنوان مثال، اگر این جمله “هوش مصنوعی در حال تحول است” را درنظر بگیرید، مدل از زمینه برای پیشبینی کلمات احتمالی مانند “آینده” یا “جامعه” استفاده میکند.
این رویکرد شامل آموزش یک مدل از حالت اولیه آن با استفاده از مجموعه دادههای گسترده است. به عنوان مثال، BloombergGPT، یک هوش مصنوعی تخصصی در امور مالی، با استفاده از دادههای حوزه مالی آموزش داده شد که به آن امکان میدهد در صنعت مالی عملکرد فوقالعادهای داشته باشد. با این حال، این روش به مقادیر عظیمی از داده (اغلب در سطح ترابایت)، منابع GPU قابل توجه و سرمایهگذاریهای زمانی و مالی قابل توجه نیاز دارد.
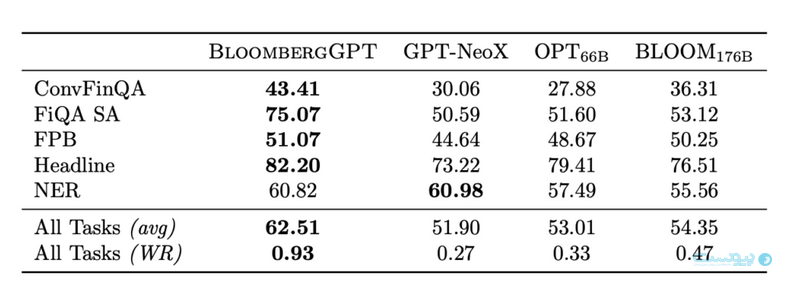
جدولی که نمایش داده شده است؛ مقایسهای بین عملکرد چندین مدل زبانی بزرگ (LLM) را در انجام چندین کار مختلف نشان میدهد. مدلهای زبانی بزرگ، مدلهای هوش مصنوعی هستند که بر روی حجم عظیمی از متن آموزش دیدهاند و میتوانند کارهایی مانند ترجمه، خلاصهسازی متن و تولید متن خلاقانه را انجام دهند.
اعداد داخل جدول، نمرات عملکرد مدلها در هر کار را نشان میدهند. این نمرهها معمولاً بین 0 تا 100 هستند و هرچه نمره بالاتر باشد، نشاندهنده عملکرد بهتر مدل است.
این جدول به ما کمک میکند تا عملکرد مدلهای زبانی مختلف را در کارهای مختلف مقایسه کنیم و درک کنیم که کدام مدل برای چه کاری مناسبتر است. همچنین، این جدول نشان میدهد که تحقیقات در زمینه مدلهای زبانی بزرگ در حال پیشرفت است و مدلهای جدید با عملکرد بهتر به طور مداوم در حال توسعه هستند.
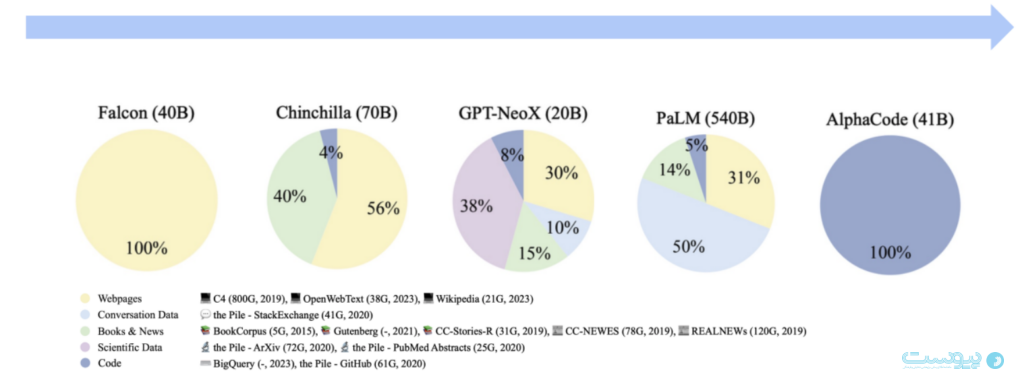
DAPT مفهومی است که برای ایجاد مدلهای هوش مصنوعی بهینهسازی شده برای دامنههای خاص (مانند مالی، مراقبتهای بهداشتی، حقوقی) طراحی شده است. این رویکرد شامل آموزش بیشتر یک مدل هوش مصنوعی مولد از پیش آموزشدیده با دادههای دامنه خاص است.
به عنوان مثال، در حوزه پزشکی، مدل با استفاده از دادههایی مانند مقالات تحقیقاتی، فرهنگ لغتهای اصطلاحات پزشکی و گزارشهای بالینی آموزش داده میشود تا آن را برای تخصص در مراقبتهای بهداشتی آماده کند. برخلاف مجموعه دادههای گستردهای که در پیشآموزش عمومی استفاده میشوند، DAPT کارآمدتر عمل میکند؛ زیرا از مقدار نسبتاً کمتری از دادههای دامنه خاص استفاده میکند.
در واقع، شرکت هوش مصنوعی Datumo با ارائه راهکارهای دادهمحور پروژههایی در حوزههایی مانند مالی، مخابرات و فناوری را انجام داده است. DAPT در مدلهای هوش مصنوعی آن با استفاده از مجموعه دادههای تخصصی در بخشهای مخابرات و مالی اعمال شده است و مدلهای هوش مصنوعی متناسب با نیازها و اهداف مشتریان را ساخته است.
پسآموزش فرآیند تنظیم دقیق یک مدل است که قبلاً پیشآموزش دیده است تا آن را برای وظایف خاص بهینه کند. این مرحله به دو مرحله اصلی تقسیم میشود:
برای اینکه مدل هوش مصنوعی مولد بتواند بهتر منظور کاربر را بفهمد یا وظایف مشخصی را دقیقتر انجام دهد، آن را بهطور ویژه تنظیم میکنند. در این کار، معمولاً از روشی به نام PEFT استفاده میشود. در روش PEFT بهجای تغییر تمام بخشهای مدل، فقط یک بخش کوچک و اضافهشده از مدل را بهروزرسانی میکنند. این کار باعث میشود تنظیم مدل سریعتر و کارآمدتر باشد. با استفاده از دادههایی که پاسخهای درست و مشخص دارند (مثل سؤالاتی که جواب درستشان معلوم است)، این روش عملکرد مدل را در کارهایی مثل پاسخ دادن به سوالات، خلاصه کردن متن و دستهبندی محتوا بهتر میکند.
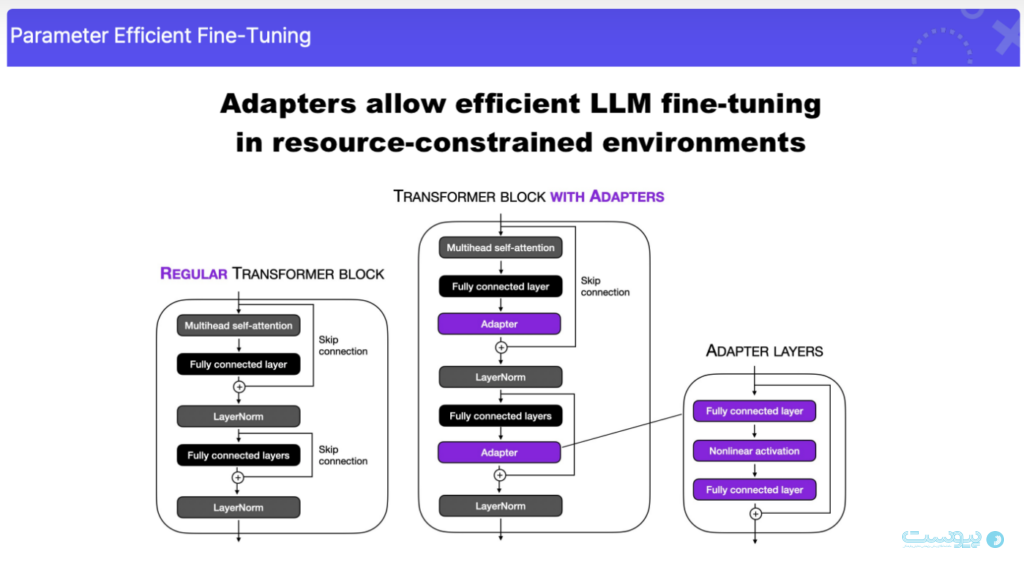
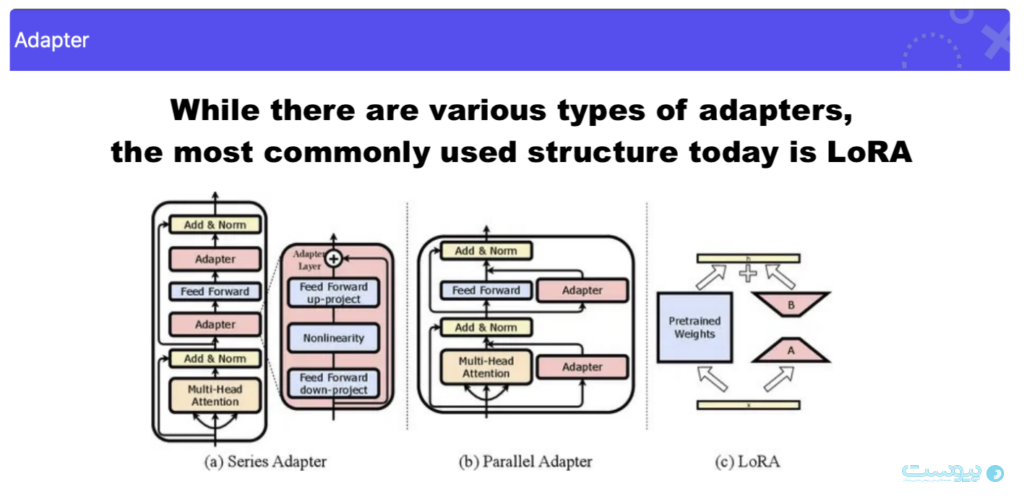
یک روش قابل توجه تحت PEFT، LoRA (Low-Rank Adaptation) است که تنظیم دقیق با عملکرد بالا را با حداقل داده و منابع محاسباتی امکانپذیر میکند.
در حالی که پیشآموزش مدل هوش مصنوعی مولد را با درک اساسی از الگوها و ساختارهای متن تجهیز میکند، پسآموزش این پایه را اصلاح میکند تا اطمینان حاصل شود که مدل وظایف خاص را با دقت و کارایی انجام میدهد.
این مرحله شامل آموزش مدل برای تولید پاسخهای طبیعیتر با استفاده از بازخورد کاربر است. ارزیابان انسانی خروجیهای مدل را به عنوان “پسندیده” یا “ناپسندیده” رتبهبندی میکنند و به اصلاح پاسخهای آن کمک میکنند. از طریق این فرآیند، هوش مصنوعی درک بهتری از قصد کاربر پیدا میکند و پاسخهای انسانمانندتری تولید میکند.
از طریق این دو مرحله، هوش مصنوعی مولد تکامل مییابد تا نه تنها متن، بلکه دادههای چندوجهی را نیز پردازش کند و نتایج بهینهسازی شدهای را برای برآورده کردن نیازهای کاربر ارائه دهد.
برای اینکه هوش مصنوعی مولد به ابزاری واقعاً کاربردی تبدیل شود، لازم است که بتواند نیت کاربران را بهخوبی تشخیص دهد و انتظارات آنها را برآورده کند. برای رسیدن به این هدف، هوش مصنوعی باید درک عمیقی از رفتار و خواستههای انسانی داشته باشد. تاکنون درباره نقش یادگیری تقویتی از طریق بازخورد انسانی (RLHF) در بهبود درک مدلها از قصد کاربر و تولید پاسخهایی طبیعیتر صحبت شده است. همچنین موضوع همترازی انسانی (Human Alignment) بهطور دقیقتری باید بررسی شود تا روند فناورانه تا حد خوبی شفاف میشود و RLHF را بهعنوان یکی از روشهای کلیدی در این حوزه میتوان بررسی کرد.






