
وقتی ترس از هوش مصنوعی، خودش به یک تهدید تبدیل میشود
هوش مصنوعی سالهاست مخالفان جدی دارد. از پژوهشگران و دانشمندانی که درباره خطرات آن هشدار…
۲۱ تیر ۱۴۰۵






پرستو توکلی
۲۳ خرداد ۱۴۰۴
زمان مطالعه : ۱۳ دقیقه

Llama (لاما) یک خانواده از مدلهای زبانی بزرگ باز (LLM) و مدلهای چندرسانهای بزرگ (LMM) از شرکت متا است. جدیدترین نسخه، لاما ۴ است. این اساساً پاسخ شرکت مادر فیسبوک به OpenAI و گوگل Gemini است اما با یک تفاوت کلیدی: تمام مدلهای لاما بهصورت آزاد در دسترس تقریباً همه افراد برای استفاده پژوهشی و تجاری قرار دارند. این موضوع بسیار مهمی است و همین باعث شده که مدلهای مختلف لاما در میان توسعهدهندگان هوش مصنوعی محبوبیت زیادی پیدا کنند. بیایید بررسی کنیم که «مجموعه» مدلهای لامای متا چه چیزهایی را ارائه میدهد.
مدل زبانی بزرگ لاما (LLaMA) یک مدل هوش مصنوعی متنباز توسعهیافته توسط شرکت متا (مالک اینستاگرام، واتساپ و فیسبوک) است که برای پردازش زبان طبیعی (NLP) مانند تولید متن، پاسخ به سوالات و ترجمه طراحی شده است.
لاما یک خانواده از LLMها (و LLMهایی با قابلیتهای بصری، یا همان LMM) و مشابه GPT از OpenAI و Gemini از گوگل است. در حال حاضر، شمارهگذاری نسخهها کمی درهموبرهم است. برخی مدلها به نسخه لاما ۴ رسیدهاند، در حالی که برخی دیگر هنوز در نسخههای لاما ۳.۳، ۳.۲ و ۳.۱ هستند. با انتشار بخشهای بیشتری از مجموعهٔ لاما ۴، احتمالاً مدلهای مختلف لاما ۳ کنار گذاشته خواهند شد هرچند فعلاً هنوز در دسترس و پشتیبانیشده هستند.
در زمان نگارش این مطلب، مدلهایی که از سوی متا برای دانلود در دسترساند عبارتاند از:
همچنین دو مدل منتشرنشدهٔ لاما ۴ وجود دارد:
بهطور کلی، همه مدلهای لاما بر اساس اصول بنیادین یکسانی عمل میکنند. آنها از انواع مختلف معماری ترنسفورمر استفاده میکنند و با استفاده از پیشتمرین (pre-training) و تنظیم دقیق (fine-tuning) توسعه یافتهاند. بزرگترین تفاوتها این است که مدلهای لاما ۴ بهطور بومی چندرسانهای هستند و از معماری ترکیب متخصصان (Mixture-of-Experts یا MoE) استفاده میکنند که در ادامه بیشتر توضیح میدهیم.
وقتی یک متن یا ورودی متنی به مدل وارد میکنید، این مدل تلاش میکند با استفاده از شبکهٔ عصبی خود، که یک الگوریتم آبشاری با میلیاردها متغیر (که به آنها «پارامتر» گفته میشود) است و بر پایهٔ مغز انسان مدلسازی شده، محتملترین ادامهٔ متن را پیشبینی کند. (در مدلهایی که از تصویر پشتیبانی میکنند، فرایندی مشابه برای تصاویر انجام میشود.)
مدلهای مختلف لاما ۳، توازنهای متفاوتی میان قیمت و عملکرد ارائه میدهند. برای مثال، مدلهای کوچک مانند Llama 3.1 با ۸ میلیارد پارامتر و Llama 3.2 با با ۳ میلیارد پارامتر طوری طراحی شدهاند که روی دستگاههای لبهای (edge devices) مانند گوشیهای هوشمند و کامپیوترها اجرا شوند، یا اینکه در سختافزارهای قدرتمند، با سرعت و هزینه بسیار کم کار کنند. بزرگترین مدل، یعنی Llama 3.1 با ۴۰۵ میلیارد پارامتر، در اکثر شرایط بیشترین عملکرد را دارد، اما بیشترین منابع را نیز برای اجرا نیاز دارد. مدلهای Vision برای کاربردهای چندرسانهای طراحی شدهاند، و Llama 3.3 70B توازن بسیار خوبی بین عملکرد و هزینه دارد.
دو مدل لاما ۴—یعنی Llama 4 Scout و Llama 4 Maverick—از رویکردی متفاوت در مدیریت پارامترها استفاده میکنند که به آن معماری ترکیب متخصصان (Mixture-of-Experts یا MoE) گفته میشود. Llama 4 Scout در مجموع ۱۰۹ میلیارد پارامتر دارد، اما فقط ۱۷ میلیارد از آنها را بهصورت همزمان استفاده میکند. Llama 4 Maverick در مجموع ۴۰۰ میلیارد پارامتر دارد، اما باز هم در بیشترین حالت فقط ۱۷ میلیارد را فعال میکند. این رویکرد باعث میشود مدلهای هوش مصنوعی هم قدرتمندتر و هم بهینهتر باشند، هرچند توسعهٔ آنها پیچیدهتر است.
علاوه بر Scout و Maverick، متا مدل Llama 4 Behemoth را نیز معرفی کرده است. این مدل هم از معماری MoE استفاده میکند و دارای ۲ تریلیون پارامتر در مجموع است، که ۲۸۸ میلیارد پارامتر از آن بهصورت فعال استفاده میشوند. این مدل هنوز در حال آموزش است.
یکی از غیبتهای قابلتوجه در معرفی لاما ۴، نبود هرگونه مدل استدلالی (reasoning model) است. یک صفحهٔ تبلیغاتی برای آن منتشر شده، بنابراین بهزودی عرضه خواهد شد، اما فعلاً مجموعه لاما محدود به مدلهای بدون قابلیت استدلال است.
دستیار هوش مصنوعی متا که در فیسبوک، مسنجر، اینستاگرام و واتساپ تعبیه شده، اکنون از لاما ۴ استفاده میکند (حداقل در ایالات متحده). بهترین مکان برای امتحان کردن آن، وباپلیکیشن اختصاصی آن است.
برای استفاده از مدلهای LLaMA چند روش مختلف وجود دارد. اگر بخواهید بدون نیاز به سختافزار قدرتمند و صرفاً از طریق اینترنت از این مدل استفاده کنید، پلتفرمهایی مانند Hugging Face این امکان را فراهم کردهاند. در این پلتفرمها با ثبتنام و دریافت دسترسی میتوان از مدلها در قالب فضای آزمایش آنلاین یا API استفاده کرد. همچنین برخی سرویسهای گفتوگومحور مانند Poe.com یا Perplexity.ai نیز از مدلهای LLaMA پشتیبانی میکنند و به کاربر امکان گفتوگو با این مدلها را میدهند.
در صورتی که علاقهمند باشید LLaMA را روی سیستم شخصی خود اجرا کنید، نیاز به سختافزاری با توان پردازشی بالا بهویژه کارت گرافیک قدرتمند خواهید داشت. برای این منظور میتوان از ابزارهای متنبازی مانند llama.cpp یا text-generation-webui استفاده کرد. این ابزارها به شما اجازه میدهند مدل را به صورت محلی اجرا کرده و از آن برای کاربردهایی مانند تولید متن، پاسخ به پرسشها یا تحلیل زبان استفاده کنید.
از نظر حقوقی، مدلهای LLaMA بهصورت متنباز در دسترس هستند اما استفاده تجاری از آنها نیازمند دریافت مجوز رسمی از شرکت متا است. در عوض، استفادههای پژوهشی، آموزشی و شخصی با محدودیت کمتری مواجهاند.
لاما ۴ چگونه کار میکند؟
لاما ۴ از معماری «ترکیب متخصصان» (Mixture-of-Experts یا MoE) استفاده میکند. مدل Scout دارای ۱۰۹ میلیارد پارامتر در قالب ۱۶ متخصص است و در هر بار اجرا فقط ۱۷ میلیارد پارامتر را فعال میکند. مدل Maverick دارای ۴۰۰ میلیارد پارامتر در قالب ۱۲۸ متخصص است و آن هم فقط ۱۷ میلیارد پارامتر را بهصورت همزمان فعال میکند.
هر «متخصص» (expert) یک زیرسیستم است که در یک حوزهٔ خاص تخصص دارد. اگرچه مدلهای زبانی بزرگ (LLMها) دقیقاً مانند انسانها با زبان کار نمیکنند، اما اگر تصور کنید که Scout دارای یک متخصص در ادبیات انگلیسی، یک متخصص در کدنویسی کامپیوتر و یک متخصص در زیستشناسی است، چندان دور از ذهن نیست. مدل Maverick، با داشتن تعداد بیشتری پارامتر و متخصص، زیرسیستمهای حتی تخصصیتری دارد؛ مثلاً بهجای داشتن یک متخصص در زیستشناسی، یک متخصص در میکروبیولوژی و یکی در جانورشناسی دارد.
نکتهٔ کلیدی این است که وقتی شبکهٔ MoE یکی از مدلهای لاما ۴ فعال میشود، یک «شبکهٔ دروازهای» (gating network) انتخاب میکند که کدامیک از متخصصان مناسبترین است تا در کنار یک متخصص مشترک که همیشه فعال است، بهکار گرفته شود. (فرض کنید آن متخصص مشترک مسئول دانش عمومی است.) اگر از Scout سؤالی دقیق درباره شکارچیان رأس زنجیرهٔ غذایی بپرسید، این مدل با فعال کردن متخصص زیستشناسی و متخصص مشترک پاسخ خواهد داد. اگر دربارهٔ فیلم «آروارهها» (Jaws) از آن توضیح بخواهید، متخصص ادبیات انگلیسی و متخصص مشترک فعال میشوند. به این ترتیب، تنها ۱۷ میلیارد از مجموع ۱۰۹ میلیارد پارامتر فعال میشوند تا پاسخ تولید شود.
در مقابل، اگر همان پرسشها را برای مدل Llama 3.3 با ۷۰ میلیارد پارامتر بفرستید، هر بار تمام ۷۰ میلیارد پارامتر فعال میشود. البته این سادهسازی زیادی است. LLMها با استفاده از «توکنها» کار میکنند که در فضایی چندبعدی از بردارها نگاشته میشوند. هر توکن، یک کلمه یا قطعهٔ معنایی است که به مدل کمک میکند معنا را به متن نسبت دهد و ادامهٔ متن را بهشکل محتملی پیشبینی کند. اگر کلمات «Apple» و «iPhone» بهطور مداوم کنار هم ظاهر شوند، مدل میفهمد که این دو مفهوم به هم مرتبطاند—و با مفاهیمی مانند «apple»، «banana» و «fruit» متفاوتاند—و این بر اساس نحوهٔ ارتباط بین بردارهاست. هر متخصص در جریان آموزش مدل شکل میگیرد و بخشی از فضای برداری را در بر میگیرد، نه الزاماً یک موضوع مشخص مثل زیستشناسی، اما ایدهٔ کلی همچنان معتبر است.
برای رسیدن به این نقطه، مدلهای لاما ۴ با تریلیونها توکن متنی و همچنین میلیاردها تصویر آموزش داده شدهاند. بخشی از دادهها از منابع عمومی مانند Common Crawl (آرشیوی از میلیاردها صفحهٔ وب)، ویکیپدیا، و کتابهای دامنهٔ عمومی پروژه گوتنبرگ به دست آمدهاند، و بخشی نیز دادههای مصنوعی هستند که توسط مدلهای هوش مصنوعی قبلی تولید شدهاند. (هیچیک از این دادهها از کاربران متا گرفته نشده است.)
علاوه بر آموزش اختصاصی خودشان، Scout و Maverick از مدل Behemoth نیز «تقطیر» شدهاند؛ مدلی که متا ادعا میکند «یکی از هوشمندترین مدلهای زبانی جهان» است. در اصل، این بدان معناست که Scout و Maverick طوری آموزش دیدهاند که خروجیهای Behemoth را تقلید کنند، که این به آنها کمک میکند تا با وجود کوچکتر بودن، عملکردی مشابه ارائه دهند.
البته، آموزش یک مدل هوش مصنوعی با دادههای اینترنت آزاد، میتواند منجر به نژادپرستی و محتوای فاجعهبار دیگر شود؛ بنابراین متا از راهبردهای آموزشی دیگری نیز بهره گرفته است، از جمله تنظیم با نظارت (supervised fine-tuning)، یادگیری تقویتی آنلاین، و بهینهسازی مستقیم ترجیحات. اینها در کنار هم به هدایت مدل به سمت تولید پاسخهای مفید و مناسب کمک میکنند.
تمام مدلهای لاما بهعنوان پایهای برای توسعهدهندگان طراحی شدهاند تا بر اساس آنها مدلهای اختصاصی خود را بسازند. اگر میخواهید مدلی زبانی بسازید که خلاصهٔ مقالات را به سبک و صدای خاص برند شرکت شما تولید کند، میتوانید مدلهای لاما را با دهها، صدها یا حتی هزاران نمونه آموزش دهید و مدلی بسازید که دقیقاً همین کار را انجام دهد. بهطور مشابه، میتوانید یکی از این مدلها را برای پاسخ به درخواستهای پشتیبانی مشتری خود تنظیم کنید، با ارائهٔ اطلاعاتی مانند پرسشهای پرتکرار و گزارشهای چت. یا میتوانید بهسادگی یکی از مدلهای لاما را بازآموزی کرده و مدل زبانی کاملاً مستقلی برای خودتان بسازید.
لاما در برابر GPT، Gemini و دیگر مدلهای هوش مصنوعی چگونه با هم مقایسه میشوند؟
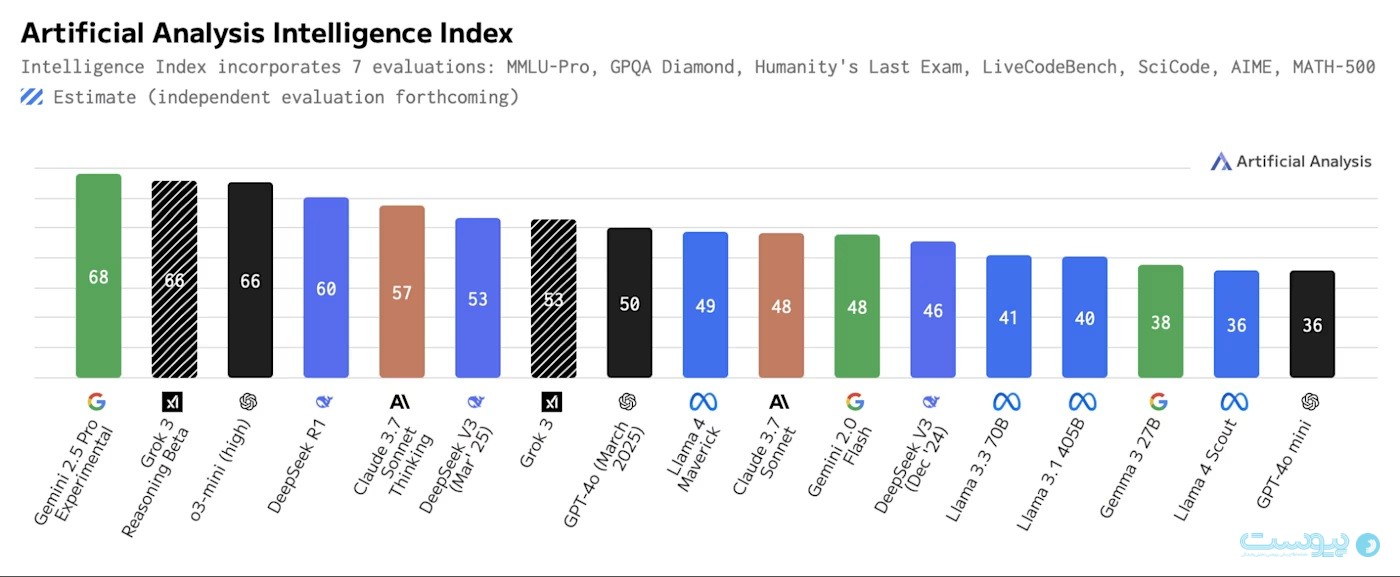
Llama 4 Maverick و Scout مدلهای متنباز قدرتمندی هستند، اگرچه بهترین عملکرد در کلاس خود را ارائه نمیدهند. بهویژه، نبود یک مدل «استدلالی» (reasoning model) تا به این لحظه، آنها را از صدر اکثر ارزیابیها (benchmarks) دور نگه داشته است.
Llama 4 Maverick با مدلهایی مانند DeepSeek V3، Grok 3، GPT-4o، Claude Sonnet 3.7 و Gemini 2.0 Flash رقابت میکند. همانطور که در نمودار بالا از Artificial Analysis دیده میشود، این مدل یک مدل غیراستدلالی مناسب است، هرچند مزیت کلیدی آن این است که قویترین مدل چندحالتهٔ متنباز (multimodal) و قویترین مدل زبانی غیرچینی متنباز است.
ساختار MoE (ترکیب متخصصان) در Maverick باید اجرای آن را از نظر هزینه مقرونبهصرفه کند، بهویژه در مقایسه با مدلهای اختصاصی مانند GPT-4o. یک نسخهٔ آزمایشی از آن هماکنون در حوزهٔ چتباتها در رتبهٔ دوم قرار دارد، بنابراین قطعاً آیندهدار است. این مدل دارای یک پنجرهٔ متنی (context window) به اندازهٔ یک میلیون توکن است، که مقدار خوبی است، اما توسط مدلهای دیگر نیز مطابقت داده شده است.
Llama 4 Scout با GPT-4o mini رقابت میکند، اما از دو جهت جالب توجه است. نخست، طراحی آن به گونهای است که بر روی تنها یک GPU مدل H100 اجرا میشود. گرچه این GPU در سطح سرور قرار دارد، اما مدلهای بزرگتر معمولاً روی خوشهای از چند GPU اجرا میشوند، نه یک کارت منفرد. دوم، Scout دارای یک پنجرهٔ متنی ۱۰ میلیون توکنی است، که واقعاً در کلاس خود بینظیر است. نکتهٔ منفی این است که در حال حاضر هیچ ارائهدهندهای برای ارائهٔ این قابلیت آماده نیست.
در حالی که متا برخی امتیازهای اولیهٔ عملکرد برای مدل Behemoth منتشر کرده و ظاهراً در برخی معیارها از GPT-4.5 پیشی گرفته است اما سرعت تغییرات در دنیای هوش مصنوعی چنان زیاد است که نباید زیاد روی آن تمرکز کرد تا زمانی که واقعاً در دسترس قرار گیرد. بهطور مشابه، هرگونه مدل استدلالی از خانوادهٔ Llama 4 قطعاً اهمیت زیادی خواهد داشت.
لاما ۴ بهوضوح آیندهٔ خانوادهٔ Llama است، اما مدلهای Llama 3 همچنان گزینههای خوبی باقی ماندهاند. دیگر نمیتوان گفت که آنها عملکردی در سطح پیشرفتهترین مدلها دارند، اما میتوانند مقرونبهصرفه و مؤثر باشند.
چرا لاما اهمیت دارد؟
اکثر مدلهای زبانی بزرگی که شنیدهاید—مدل o1 و GPT-4o از OpenAI، Gemini از گوگل، و Claude از Anthropic—همگی اختصاصی و متنبستهاند. پژوهشگران و کسبوکارها میتوانند از APIهای رسمی برای دسترسی به آنها استفاده کنند و حتی نسخههای خاصی از آنها را برای پاسخهای سفارشی تنظیم کنند، اما واقعاً نمیتوانند به عمق مدلها بروند یا بفهمند در درونشان چه میگذرد.
اما با لاما، میتوانید همین حالا مدل را دانلود کنید، و اگر دانش فنی لازم را دارید، آن را روی یک سرور ابری اجرا کنید یا حتی در کد آن کاوش کنید. میتوانید مدلهای Llama 3 را روی برخی کامپیوترها اجرا کنید، اگرچه Scout و Maverick از خانوادهٔ Llama 4 برای استفاده خانگی بیش از حد بزرگ هستند.
و حتی مفیدتر از آن، میتوانید این مدلها را روی پلتفرمهایی مانند Microsoft Azure، Google Cloud، Amazon Web Services و دیگر زیرساختهای ابری راهاندازی کنید تا اپلیکیشن مبتنی بر مدل زبانی خود را اجرا کنید یا آن را با دادههای اختصاصی خود آموزش دهید تا نوع متنی که نیاز دارید را تولید کند. فقط مطمئن شوید که راهنمای متا دربارهٔ استفادهٔ مسئولانه از Llama را مطالعه کردهاید—چون مجوز آن کاملاً شبیه مجوزهای متنباز سنتی نیست.
با این حال، متا با ادامه دادن به رویهٔ باز نگه داشتن لاما، روند توسعهٔ اپلیکیشنهای هوش مصنوعی را برای سایر شرکتها بسیار آسانتر کرده است، بهشرطی که آنها به سیاستهای استفادهٔ مجاز پایبند بمانند. نکتهٔ نگرانکننده این است که کاربران اتحادیه اروپا در حال حاضر از استفاده از Llama 4 محروم هستند، اما باید دید که آیا این موضوع با گسترش عرضه تغییر خواهد کرد یا نه. تنها محدودیت بزرگ دیگر مجوز لاما این است که شرکتهایی با بیش از ۷۰۰ میلیون کاربر ماهانه باید برای استفاده از لاما مجوز ویژه بگیرند؛ بنابراین شرکتهایی مانند اپل، گوگل و آمازون باید مدلهای زبانی اختصاصی خودشان را توسعه دهند.
در نامهای که همراه با انتشار Llama 3.1 منتشر شد، مدیرعامل مارک زاکربرگ بسیار شفاف دربارهٔ برنامههای متا برای باز نگه داشتن لاما صحبت کرد: من باور دارم که متنباز بودن برای آیندهای مثبت در حوزهی هوش مصنوعی ضروری است. هوش مصنوعی بیش از هر فناوری مدرن دیگری پتانسیل دارد که بهرهوری، خلاقیت و کیفیت زندگی انسان را افزایش دهد — و رشد اقتصادی را شتاب ببخشد، در حالی که پیشرفت در پژوهشهای پزشکی و علمی را نیز ممکن میسازد. متنباز بودن تضمین میکند که افراد بیشتری در سراسر جهان به منافع و فرصتهای هوش مصنوعی دسترسی داشته باشند، قدرت در دستان تعداد معدودی شرکت متمرکز نشود، و این فناوری بتواند به شکلی متعادلتر و ایمنتر در سراسر جامعه بهکار گرفته شود.
و واقعاً، این موضوع بسیار هیجانانگیز است البته به شرطی که مسئلهی اتحادیه اروپا حل شود. بله، متا از اینکه تا حدی کنترل یکی از مهمترین مدلهای هوش مصنوعی را در دست دارد، بهره خواهد برد. اما توسعهدهندگان مستقل، شرکتهایی که نمیخواهند در یک سیستم بسته گرفتار شوند، و همهی کسانی که به هوش مصنوعی علاقه دارند، نیز سود خواهند برد. بسیاری از پیشرفتهای بزرگ در دنیای محاسبات در طول ۷۰ سال گذشته، بر پایهی پژوهشها و آزمایشهای متنباز بنا شدهاند، و اکنون بهنظر میرسد که هوش مصنوعی نیز یکی از آنها باشد.
در حالیکه گوگل، OpenAI و Anthropic همواره بازیگران اصلی این حوزه خواهند بود، اما آنها دیگر نخواهند توانست نوعی «خندق تجاری» یا «وابستگی مصرفکننده» ایجاد کنند که گوگل در حوزهی جستوجو و تبلیغات موفق به ساختن آن شده است.
با رها کردن Llama به دنیای بیرون، احتمالاً همیشه یک جایگزین معتبر برای هوش مصنوعیهای متنبسته وجود خواهد داشت.
منبع: zapier







