
علم پشت پرده ویرال شدن محتوا چیست
ویرال شدن یک محتوا فقط شانس یا اتفاق نیست و قطعاً تصادفی رخ نمیدهد. دلیلی…
۱۵ فروردین ۱۴۰۴






سینا حسنزاده
۱۱ مهر ۱۴۰۲
زمان مطالعه : ۱۶ دقیقه
مقاله زیر ترجمهای دقیق از نوشته خانم Beatriz Stollnitz در پلتفرم مدیوم است. ایشان یکی از توسعهدهندگان اصلی فناوریهای هوش مصنوعی و یادگیری ماشین در مایکروسافت هستند. در این مقاله به مفاهیم پایه هوش مصنوعی، شیوه کارکرد مدلهای GPT و سیر تکاملی مدلهای مختلف زبان طبیعی میپردازد.
معرفی
من در سال ۲۰۲۱، اولین خطهای کد خود را با استفاده از مدل GPT نوشتم. در آن لحظه متوجه شدم که تولید متن به نقطه عطف خود رسیدهاست. من پیش از آن، در مدرسه مدلهای زبانی متنی را از صفر نوشته بودهام و در کارکردن با دیگر سیستمهای تولید متن هم تجربه داشتهام. در نتیجه، میدانستم که چقدر دشوار است کاری کنید تا سیستمهای اینچنینی نتایج کاربردی بدهند.
فناوری GPT-3 قرار بود در داخل سرویس آژور OpenAI بهکار رود و بخشی از مراسم رونمایی آن برعهده من بود. بدین ترتیب، خوشبخت بودم که دسترسی اولیه به این هوش مصنوعی داشتم و توانستم آن را بهخاطر آمادهسازی مراسم امتحان کنم.
از جیپیتی-3 خواستم تا سندی طولانی را برایم خلاصه کند و درخواستم را به چند شکل برای او مطرح کردم. میدیدم که نتایج بسیار پیشرفتهتر از مدلهای قبلی است. فناوری جدید مرا شگفتزده کرد و باعث شد بهدنبال یادگیری شیوه پیادهسازی آن باشم.
اکنون که GPT-3.5، چت جیپیتی و GPT-4 در حال سازگاری هرچه بیشتر با مردم هستند، افراد متخصص بیشتری درباره شیوه کارکرد آنها کنجکاو شدهاند. جزئیات طرز کار هر جیپیتی اختصاصی و پیچیده است، اما مدلهای مختلف آن چند ایده اساسی را دنبال میکنند که درک آن دشوار نیست.
هدف من از نوشتن این پست، توضیح مفاهیم مدلهای زبانی بهطور کلی و مدلهای GPT بهطور اختصاصی است. شرح مفصلی که در ادامه میخوانید، به درد دانشمندان داده و مهندسان یادگیری ماشین میخورد.
بیایید با شیوه کار مدلهای زبانی مولد شروع کنیم. پایهایترین ایده به این شکل است: مدلهای زبانی n توکن را به عنوان ورودی میگیرند و یک توکن به عنوان خروجی تولید میکنند.
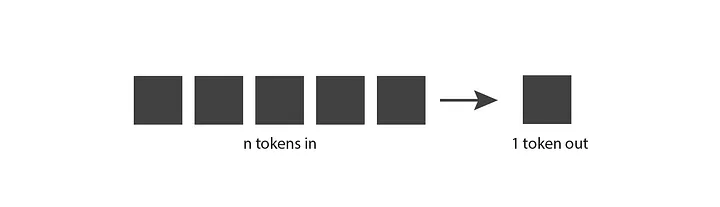
مفهوم سرراستی بهنظر میرسد، ولی برای درک عمیقتر باید بدانیم توکن چیست.
توکن تکهای متن است. کلمات رایج و کوتاه معمولا در جیپیتی OpenAI برابر با یک توکن هستند. برای مثال، کلمه We در تصویر زیر یک توکن محسوب میشود. کلمات بلند و کمتر رایج عموما به چند توکن شکسته میشوند. برای مثال، کلمه «anthropomorphizing» در تصویر زیر تبدیل به سه توکن شدهاست. حروف مخففی مانند ChatGPT بسته به میزان رایجبودن آن حروف در کنار هم، یک توکن در نظر گرفتهشده یا تبدیل به چند توکن میشوند.
شما میتوانید متن خود را در صفحه Tokenizer اوپنایآی وارد کرده و ببینید تبدیل به چند توکن میشود. خاطرتان باشد که توکنیزاسیون GPT-3 برای متنها و توکنیزاسیون Codex برای کدها بهکار میرود. ما تنظیمات پیشفرض GPT-3 را نگه میداریم.

شما همچنین میتوانید از کتابخانه منبعباز OpenAI یعنی tiktoken برای توکنایزکردن با استفاده از پایتون نیز استفاده کنید. OpenAI چندین توکنایزکننده دیگر هم دارد که هرکدام کمی با دیگری متفاوت است. ما در کد زیر از توکنایزر برای داوینچی، یکی از مدلهای GPT-3، استفاده کردیم. بدین ترتیب، شما هنگام استفاده از UI، رفتار انطباقیافتهای را میبینید.
import tiktoken
# Get the encoding for the davinci GPT3 model, which is the "r50k_base" encoding.
encoding = tiktoken.encoding_for_model("davinci")
text = "We need to stop anthropomorphizing ChatGPT."
print(f"text: {text}")
token_integers = encoding.encode(text)
print(f"total number of tokens: {encoding.n_vocab}")
print(f"token integers: {token_integers}")
token_strings = [encoding.decode_single_token_bytes(token) for token in token_integers]
print(f"token strings: {token_strings}")
print(f"number of tokens in text: {len(token_integers)}")
encoded_decoded_text = encoding.decode(token_integers)
print(f"encoded-decoded text: {encoded_decoded_text}")text: We need to stop anthropomorphizing ChatGPT. total number of tokens: 50257 token integers: [1135, 761, 284, 2245, 17911, 25831, 2890, 24101, 38, 11571, 13] token strings: [b'We', b' need', b' to', b' stop', b' anthrop', b'omorph', b'izing', b' Chat', b'G', b'PT', b'.'] number of tokens in text: 11 encoded-decoded text: We need to stop anthropomorphizing ChatGPT.
شما در خروجی کد میبینید که توکنایزر، ۵۰۲۵۷ توکن متفاوت دارد و هرکدام از داخل به شاخص عددی صحیح مرتبط شدهاست. یک رشته را درنظر بگیرید؛ ما میتوانیم آن را به توکنهای صحیح تقسیم و آن توکنهای صحیح را به توالی از کاراکترهای منطبق تبدیل کنیم. کدگذاری (Encode) و کدگشایی (Decode) یک رشته همیشه باید رشته اصلی را به ما برگرداند.
مثال بالا بینش خوبی از چگونگی کارکرد توکنایزر OpenAI میدهد. ممکن است برایتان سوال پیش بیاید که چرا چنین طولهایی برای توکنها انتخاب کردهاند. بیایید گزینههای ممکن دیگر را برای توکنایزکردن در نظر بگیریم. فرض کنید سادهترین شیوه پیادهسازی را امتحان میکنیم که هر حرف برابر با یک توکن است. بدین ترتیب، شکستن متنها به توکن ساده شده و تعداد کل توکنهای متفاوت نیز پایین میآید.

با این حال، ما نمیتوانیم اطلاعاتی به اندازه رویکرد OpenAI کدگذاری کنیم. ما اگر از روش حرفمحور برای مثال بالا استفاده کنیم، ۱۱ توکن تنها میتواند عبارت «We need to» را انکد کند. در عین حال، ۱۱ توکن OpenAI میتواند تمام جمله را کدگذاری کند. مشخص شد که مدلهای زبانی کنونی در حداکثر تعداد توکنهایی که میتوانند دریافت کنند محدود هستند. بنابراین، ما میخواهیم تا جای ممکن بیشترین اطلاعات را در هر توکن جمع کنیم.
حالا بیایید سناریوی هر کلمه معادل یک توکن را در نظر بگیریم. ما در مقایسه با رویکرد OpenAI، تنها به ۷ توکن برای نمایندگی جملهای مشابه نیازمندیم که موثرتر بهنظر میرسد. همچنین، جداسازی براساس کلمه در پیادهسازی نیز سادهتر است. بااین حال، مدلهای زبانی به فهرست کامل از توکنهایی نیاز دارند که ممکن است به آنها برخورد کنند. چنین چیزی برای کل کلمات امکان ندارد. اول اینکه تعداد کلمات زیادی در فرهنگ لغت وجود دارد و دوم اینکه نمیتوان پابهپای واژهشناسی حوزههای خاص و کلمات جدید اختراعشده حرکت کرد.
با این اوصاف، جای تعجب ندارد که OpenAI راهحل خود را در جایی بین این دو نقطه پیدا کردهاست. شرکتهای دیگر، توکنایزکنندههایی با رویکرد مشابه منتشر کردهاند که Sentence Piece از گوگل مثال آن است.
حالا که درک بهتری از توکنها پیدا کردیم، به نمودار اصلی خود برمیگردیم تا ببینیم میتوان کمی بهتر آن را درک کرد یا خیر. مدلهای مولد، n توکن را وارد خود میکنند که ممکن است چند کلمه، چند پاراگراف یا چند صفحه باشد. سپس، یک توکن خروجی میدهند که میتواند یک کلمه یا بخشی از باشد.

حالا قضیه کمی ملموستر شد.
البته اگر کمی با چت GPT ور رفته باشید، میدانید که نه یک توکن، بلکه هربار تعداد زیادی توکن تولید میکند. ایده پایه و ساده ما به شکل الگوی پنجره در حال گسترش (expanding window) اعمال میشود. شما n توکن ورودی میدهید و یک توکن خروجی میگیرید؛ سپس توکن خروجی را به n توکن اضافه کرده و در دور بعدی به عنوان ورودی استفاده میکنید. همین چرخه تکرار شده و هربار توکن جدیدی تولید میشود. الگوی ما تا زمانی تکرار میشود که به شرط متوقفکننده دست پیدا کند. بدین ترتیب، متوجه میشویم که تمام متن دلخواه شما تولید شدهاست.
برای مثال، زمانی که عبارت «We need to» را به مدل خود بدهیم، الگوریتم احتمالا نتیجه زیر را تولید خواهد کرد:

کسانی که کمی با چتجیپیتی کار کردهاند، میدانند که مدل آن جبرگرا نیست. به زبان سادهتر، اگر سوالی مشابه را دوبار بپرسید، احتمالا دو پاسخ کاملا متفاوت میگیرید. دلیل مسئله اینست که مدل هوش مصنوعی فقط یک توکن پیشبینیشده تولید نمیکند؛ در عوض توزیع احتمال را روی تمام توکنهای ممکن برمیگرداند. به عبارت دیگر، مسیری را برمیگرداند که هر ورودی، احتمال توکنی خاص و در حال انتخابشدن را بیان میکند. سپس، مدل مدنظر قسمتی از توزیع را نمونه میگیرد و توکن خروجی را تولید میکند.
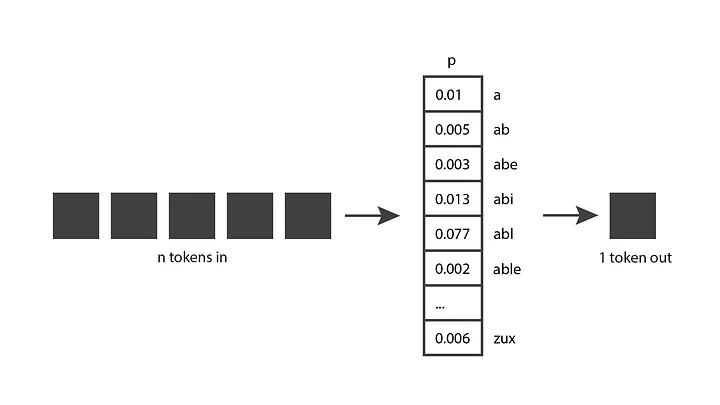
مدل چطور به چنین توزیع احتمالی رسیده است؟ فاز آموزشی (Training Phase) جواب همین سوال است. مدل در حین آموزشدیدن در معرض مقدار زیادی متن قرار میگیرد و پارامترهایش برای پیشبینی توزیع احتمالهای خوب با توجه به توالی توکنهای ورودی تنظیم میشوند. مدلهای GPT از بخش عمده اینترنت آموزش گرفتهاند، پس پیشبینیهایشان بازتاب مخلوطی از اطلاعاتی است که دیدهاند.
شما حالا درک بسیار خوبی از ایده پشت مدلهای مولد دارید. توجه کنید که من فقط ایده را شرح دادهام و هنوز به سمت الگوریتم نرفتهام. میدانیم این ایده دههها وجود داشته و طی سالها با استفاده از چندین الگوریتم پیادهسازی شدهاست. در ادامه، نگاهی به برخی از این الگوریتمها میاندازیم.
مدلهای پنهان مارکوف (HMM) در دهه 1970 میلادی بر سر زبانها افتاده بودند. نماینده داخلی این مدلها، ساختار دستور زبانی جملات (اسمها، افعال و غیره) را کدگذاری میکند و از آن دانش برای پیشبینی کلمات جدید بهره میبرد. با اینحال، مدلهای مارکوف بهخاطر فرآیندهای خود تنها جدیدترین توکن را هنگام تولید توکنی تازه در نظر میگرفتند.
بدین ترتیب، ایده n توکن ورودی و یک توکن خروجی به سادهترین شکل ممکن اجرا شدهبود؛ زیرا n همیشه معادل 1 بود. در نتیجه، مدل مارکوف نمیتوانست خروجی پیچیدهای تولید کند. مثال زیر را در نظر بگیرید:
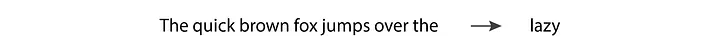
ما اگر ورودی «The quick brown fox jumps over the» را به مدل زبانی بدهیم، انتظار خروجی «lazy» را داریم. با این حال، HMM تنها آخرین توکن، یعنی the، را میبیند. چنین مقدار ناچیزی از اطلاعات قطعا نمیتواند پیشبینی مورد انتظار ما را برآورده کند.
مردم هرچه بیشتر با مدلهای HMM سروکله زدند، برایشان شفافتر شد که مدلهای زبانی به پشتیبانی بیش از یک توکن نیازمند هستند تا خروجی مقبولی بدهند.
N-grams در دهه 1990 میلادی به شهرت رسید، زیرا توانست محدودیت اصلی HMM را کنار بزند و بیش از یک توکن ورودی بگیرد. مدل ان-گرم احتمالا بهخوبی کلمه lazy را در مثال بالا پیشبینی میکرد.
سادهترین پیادهسازی n-gram، یک bi-gram است که توکنهای کاراکترمحور دارد. هر کاراکتر در این مدل میتواند کاراکتر بعدی را در توالی پیشبینی کند. شما با چند خط کد ساده میتوانید یکی از آنها را بسازید و شدیدا توصیه میکنم امتحان کنید.
اول، تعداد کاراکترهای متن آموزشی (اسم آن را n میگذاریم) خود را بشمارید و ماتریکس دو بعدی n در n را بسازید که با صفر شروع میشوند. هر جفت از کاراکترهای ورودی برای مکانیابی ورودی خاصی از این ماتریکس بهکار میرود. برای این کار باید ردیف مربوط به کاراکتر اول و ستون مربوط به کاراکتر دوم را انتخاب کنید.
هرچه بیشتر دادههای آموزشی را تجزیه کنید، به ازای هر جفت کاراکتر، یک عدد به سلول ماتریکس مربوطه اضافه میشود. برای مثال، اگر دادههای آموزشی شما دارای کلمه «car» باشد، شما یکی به ردیف c و ستون a و سپس، یکی به ردیف a و ستون r اضافه میکنید. وقتی شمارش را برای همه دادههای آموزشی انجام دادید، هر ردیف را با تقسیم هر سلول به کل آن، به یک توزیع احتمال تبدیل کنید.
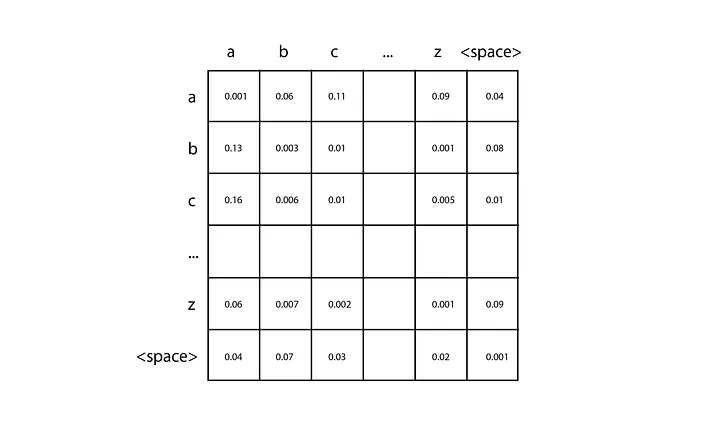
بعد، شما باید یک کاراکتر، مثلا c، به آن بدهید تا پیشبینی را آغاز کند. شما بهدنبال توزیع احتمال مربوط به ردیف c میگردید و از آن برای تولید کاراکتر بعدی نمونه میگیرید. سپس، کاراکتر تولیدشده را میگیرید و فرآیند را تکرار میکنید تا به شرط متوقفکننده برسید. n-گرمهای سطح بالا از ایده مشابهی پیروی میکنند ولی قادرند بهدنبال توالی طولانیتری از توکنهای ورودی با استفاده از تانسورهای n بعدی بگردند.
پیادهسازی n-گرمها ساده است. با اینحال، از آنجایی که با افزایش توکنهای ورودی، اندازه ماتریکس بهطور نمایی رشد میکند، n-گرمها نمیتوانند از پس تعداد زیادی توکن بربیایند. تنها چند توکن ورودی لازم است تا نتواند نتیجه خوبی تولید کند. تکنیک جدیدی برای پیشرفت فرآیند در این حوزه نیاز است.
در دهه 2000 میلادی، شبکههای عصبی مکرر (RNNs) بهخاطر پدیرفتن تعداد بسیاری زیادی از توکنهای ورودی نسبت به تکنیکهای پیشین محبوبیت بالایی پیدا کردند. LSTM و GRU که نوعی RNN هستند، بهطور خاص مورد استفاده قرار گرفتند و ظرفیت خود را در تولید نتایج خوب ثابت کردند.
RNN نوعی شبکه عصبی است، اما معماریشان برخلاف شبکههای عصبی فیدفوروارد سنتی، میتواند هر تعداد ورودی را بپذیرد و هر تعداد خروجی نیز تولید کند. برای مثال، ما اگر توکنهای ورودی We، need و to را به RNN بدهیم و بخواهیم تا نقطه کامل چند توکن دیگر تولید کند، احتمالا به ساختار زیر میرسیم:
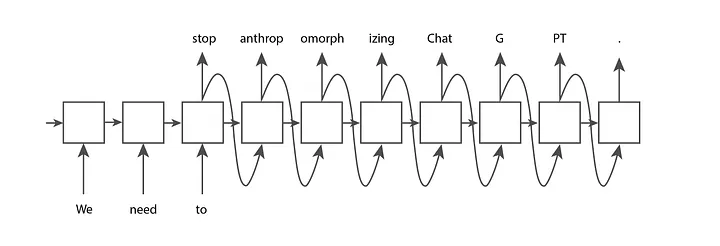
هرکدام از گرههای ساختار بالا وزن مشابهی دارند. میتوانید اینطور ببینید که یک گره به خودش متصل شده و مکررا اجرا میشود (بههمین خاطر اسم آن recurrent است) یا میتوانید به شکل گسترشیافتهی تصویر بالا به آن نگاه کنید.
یکی از ظرفیتهای اضافهشده به LSTM و GRU نسبت به نسخه پایه RNN، حضور سلول حافظه داخلی است که از هر گره به گره بعدی عبور میکند. بدین ترتیب، گرهها بعدا جنبههای خاصی از گرههای قبلی را بهخاطر میسپارند که برای پیشبینی خوب متنها ضروری است.
RNN با اینحال در توالیهای طولانی متون به مشکل ناپایداری برمیخورد. شیبها در این مدل به رشد نمایی (شیب در حال انفجار) یا کاهش به سمت صفر (شیب در حال محوشدن) میل میکنند که اجازه یادگیری بیشتر به مدل را نمیدهد.
LSTM و GRU مشکل شیب در حال محوشدن را تقلیل دادهاند اما بهطور کامل جلوی آن را نگرفتهاند. بنابراین، مدل مدنظر در عمل محدودیتهایی برای ورودیهای طولانی دارد، گرچه معماری آن در تئوری اجازه ورودی با هر طولی را میدهد. دوباره میگویم که کیفیت متنهای تولیدی به تعداد توکنهای ورودی بستگی دارد که الگوریتم آنها را پشتیبانی کند. پس در اینجا نیاز به پرش از روی مانعی دیگر داریم.
گوگل در سال ۲۰۱۷ مقالهای درباره معرفی ترانسفورمرها منتشر کرد و ما را به سمت عصر جدید تولید متون هل داد. ترانسفورمرها از معماری بهره میبردند که اجازه ورود حجم زیادی توکن را میداد و مشکل ناپایداری شیب در RNN را از بین میبرد.
مدل جدید گوگل، تطبیقپذیری بالایی داشت و قادر به استفاده از قدرت کارتهای گرافیکی بود. امروزه از ترانسفورمرها زیاد استفاده میشود. آنها همان فناوری هستند که شرکت OpenAI برای آخرین مدلهای تولید متن GPT خود انتخاب کردهاست.
پایه اصلی ترانسفورمرها، مکانیزم توجه است اجازه میدهد مدل به برخی از ورودیها توجه بیشتری نشان دهد؛ مکان قرارگیری آن ورودی در توالی نیز اهمیتی ندارد. برای مثال، جمله زیر را در نظر بگیرید:

در این سناریو، وقتی مدل به پیشبینی فعل bought میپردازد، باید زمان گذشته فعل یعنی went را تطبیق دهد. برای این کار، مدل باید به توکن went توجه زیادی را معطوف کند. در واقع، احتمالا توجه بیشتری به توکن went نسبت به توکن and، علی رغم حضور زودتر went نسبت به and در توالی ورودیها، نشان میدهد.
چنین رفتار توجه گزیدهای در مدلهای GPT بهخاطر ایدهای بدیع در مقاله سال ۲۰۱۷ اجرایی شد؛ استفاده از لایه توجه چندسر نقابزده. بیایید این اصطلاح را بشکنیم و وارد لایه عمیقتری از معنای زیراصطلاحات آن بشویم:
توجه: لایه توجه دارای ماتریکسی از اوزان است که نماینده قدرت رابطه بین موقعیت توکنهای جفتی در جمله ورودی هستند. این وزنها در طول آموزش یاد گرفته میشوند. اگر وزن مربوط به یک جفت موقعیت زیاد باشد، سپس، دو توکن حاضر در آن موقعیت تاثیر زیادی روی یکدیگر میگذارند. همین مکانیزم است که باعث میشود ترانسفورمر توجه بیشتری به برخی از توکنها بکند و مکان قرارگیری آنها در جمله برایش اهمیت نداشته باشد.
نقابزده: لایه توجه پوشیدهشده است اگر ماتریکس به رابطه بین هر موقعیت توکن و موقعیتهای قبل از خودش در ورودی محدود شده باشد. مدلهای GPT از همین نکته برای تولید متن استفاده میکنند، زیرا توکن خروجی تنها میتواند به توکنهای قبل از خود بستگی داشته باشد.
چندسر: ترانسفورمر از لایه توجه چندسر نقابزده استفاده میکند؛ زیرا دارای چند لایه نقابزده است که بهطور موازی عملیات را انجام میدهند.
سلول حافظه در LSTM و GRU همچنین توکنهای بعدی را قادر به یادآوری برخی از جنبههای توکنهای اولیه میکنند. با این حال، اگر دو توکن مرتبط خیلی از هم دور باشند، احتمال رخدادن مشکل شیب وجود دارد. ترانسفورمر چنین مشکلی ندارد زیرا هر توکن با همه توکنهای مقدم بر آن ارتباط مستقیم دارد.
حالا که ایدههای اصلی پشت معماری ترانسفورمر بهکار رفته در مدلهای GPT را درک کردید، بیایید به تمایزهای بین مدلهای مختلف دردسترس GPT نگاهی بیندازیم.
در زمان نوشتن این مقاله، آخرین مدلهای تولید متنی که OpenAI منتشر کرده، GPT-3.5، چت GPT و GPT-4 هستند. همه این مدلها برپایه معماری ترانسفورمر طراحی شدهاند. در واقع، GPT مخفف Generative Pre-trained Transformer است.
GPT-3.5 ترانسفورمری است که بهشکل مدل completion-style آموزش دیدهاست. کاربر در این سبک، چندین کلمه ورودی میدهد و هوش مصنوعی میتواند براساس دادههای آموزشیاش، چندین کلمه بیشتر در ادامه آن تولید کند.
چت GPT از سوی دیگر، بهشکل مدل conversation-style تمرین داده شدهاست. در این سبک اگر با هوش مصنوعی مکالمه و ارتباط برقرار کنیم، جواب بهتری میگیریم. پایه و اساس چت GPT مانند GPT 3.5، مدل ترانسفورمر است اما با دادههای مکالمهای بیشتر آموزش دیدهاست. سپس، از تکنیکی به نام Reinforcement Learning with Human Feedback برای هرچه بهترکردن آن استفاده کردهاست. شرکت OpenAI تکنیک RLHF را در مقاله InstructGPT در سال ۲۰۲۲ معرفی کرد. ما داده یکسانی را در این شیوه، دوبار به هوش مصنوعی میدهیم و دو پاسخ متفاوت دریافت میکنیم.
سپس، از امتیازدهنده انسانی کمک میگیریم تا بگوید کدام پاسخ را ترجیح میدهد. انتخاب امتیازدهنده جهت بهبود مدل از طریق تنظیم دقیق استفاده میشود. تکنیک RLHF خروجیها و انتظارات انسانی را بهخوبی بر هم منطبق میکند. همین نکته از دلایل موفقیت مدلهای اخیر OpenAI بهشمار میرود.
GPT-4 از هردو سبک تکمیلکننده و مکالمهای در کنار مدل پایه متعلق به خودش استفاده میکند. مدل مخصوص GPT-4 نیز با تکنیک RLHF تمرین دادهشده تا از پس انتظارات انسانی بربیاید.
شما دو گزینه برای نوشتن کدی دارید که از مدلهای GPT استفاده میکند. گزینه اول، استفاده از API مستقیم OpenAI و گزینه دوم، استفاده از API شرکت OpenAI روی Azure است. در هر دو روش از API مشابهی استفاده میکنید.
تفاوت اصلی بین دو گزینه بالا، قابلیتهایی است که Azure برای شما فراهم میکند:
شما اگر میخواهید کدی بنویسید که از این مدلها استفاده کند، باید نسخه مدنظر خود را انتخاب کنید. فهرست زیر، نسخههایی هستند که روی Azure OpenAI Service در دسترس قرار گرفتهاند:
تفاوت دو نسخه GPT-4 در تعداد توکنهایی است که پشتیبانی میکنند. gpt-4 از 8 هزار توکن و gpt-4-32k از 32 هزار توکن پشتیبانی میکند. مدلهای GPT-3.5 در مقابل تنها از 4 هزار توکن پشتیبان میکنند.
GPT-4 گزینه گرانقیمتی است. بههمین خاطر پیشنهاد میشود تا از مدلهای دیگر استفاده کنید و در صورت نیاز ارتقا دهید.
جمعبندی
ما در این مقاله به توضیح اصول بنیادین رایج در تمامی مدلهای زبانی مولد و جنبههای تمیزدهنده آخرین مدلهای GPT از شرکت OpenAI بهطور خاص پرداختیم.
ما در مسیر مقاله روی هسته فکری مدلهای زبانی، یعنی n توکن ورودی و یک توکن خروجی، تاکید کردیم. گفتین توکنها به چه شکل تقسیم میشوند و چرا! سپس، تاریخچه تحول مدلهای زبانی از مدلهای هیدن مارکوف گرفته تا مدلهای برپایه ترانسفورمر را دنبال کردیم. در نهایت، به سراغ آخرین مدلهای برپایه ترانسفورمر GPT رفتیم، شیوه پیادهسازیشان را توضیح دادیم و نحوه نوشتن کدهایی را باز کردیم که از آن مدلها استفاده میکنند.
حالا، شما در جمعهای تخصصی حرفهای زیادی برای گفتن از مدلهای GPT دارید و میتوانید از آن در پروژههای خود نیز استفاده کنید.






