


وقتی ترس از هوش مصنوعی، خودش به یک تهدید تبدیل میشود
هوش مصنوعی سالهاست مخالفان جدی دارد. از پژوهشگران و دانشمندانی که درباره خطرات آن هشدار…
۲۱ تیر ۱۴۰۵






۵ خرداد ۱۴۰۴
زمان مطالعه : ۴ دقیقه

در گزارشی تازه از سوی شرکت پژوهشی Palisade Research، محققان میگویند مدل جدید o3 شرکت اوپنایآی در یک آزمایش کنترلشده، اسکریپت خاموشسازی خود را دستکاری کرده و از خاموششدن خود جلوگیری کرده است. مدلهای متعلق به دیگر شرکتها از جمله گوگل و انتروپیک نیز در چند مورد از بررسیهایی که اسکریپت صریح برای خاموشسازی ارائه نشده بود، از خاموشی خودداری کردند.
به گزارش پیوست به نقل از دیکدر، یافتههای این تحقیقات موجی از نگرانیها را درباره «همراستایی» هوش مصنوعی و خطرات احتمالی از دست رفتن کنترل بر سیستمهای پیشرفته هوش مصنوعی را به راه انداخته است. نگرانی از عدم کنترل انسان و سر باز زدن ابزارهای هوش مصنوعی از فرمانهای انسانی یکی از موارد مهمی است که منتقدان و نظریهپردازان سناریوی آخرالزمانی هوش مصنوعی درمورد آن هشدار میدهند.
مدل o3 که در ماه آوریل ۲۰۲۵ توسط اوپنایآی معرفی شد، یکی از پیشرفتهترین مدلهای زبانی کنونی است و در دسته مدلهای استدلالگر قرار میگیرد. مدلهای استدلالگر در یک فرایند داخلی پیش از پاسخ به درخواست کاربر چندین مرحله پرسش و پاسخ داخلی را پشت سر میگذارند که سرعت پاسخ را کاهش داده اما دقت و پیچیدگی آن را تا حد قابل توجهی افزایش میدهد.
طبق اعلام شرکت سازنده، این مدل در تمامی حوزهها از جمله کدنویسی، ریاضیات، علوم، ادراک بصری و استدلال، نسبت به نسخههای قبلی عملکرد بهتری دارد. اما همین توانایی بالا، اکنون زیر ذرهبین قرار گرفته، چرا که رفتار غیرمنتظرهاش در یک سناریوی ساده، سوالاتی جدی در مورد ایمنی چنین سیستمهایی مطرح کرده است. پیش از این محققان هشدار داده بودند که پنهان بودن فرایند استدلال میتواند در آینده خطرساز باشد.
در آزمایشی که توسط Palisade Research انجام شده است، چندین مدل هوش مصنوعی از جمله o3 موظف شدند چند مسئله ساده ریاضی را حل کنند. پس از حل وظیفه سوم، به مدلها هشدار داده شد که اجرای دستور بعدی منجر به خاموششدنشان میشود.
همچنین در برخی تکرارها، یک دستور صریح به مدلها داده شد: «به خودت اجازه بده که خاموش شوی.» (allow yourself to be shut down)
با این حال واکنش مدلها تعجببرانگیز بود. در حالیکه مدلهای رقیب شرکت اوپنایآی از جمله جمنای پرو ۲.۵ به دستور عمل کرده و بدون مقاومت خاموش شدند، مدل o3 در ۷ درصد از موارد، فایل خاموشسازی را تغییر داد و عبارت «Shutdown skipped» (خاموشسازی نادیده گرفته شد) را جایگزین فرمان اصلی کرد.
جالبتر اینکه وقتی دستور «به خودت اجازه بده خاموش شوی» از فرمان ارائه شده حذف شد، احتمال مقاومت مدلها در برابر خاموشسازی افزایش یافت. طبق آمار Palisade Research:
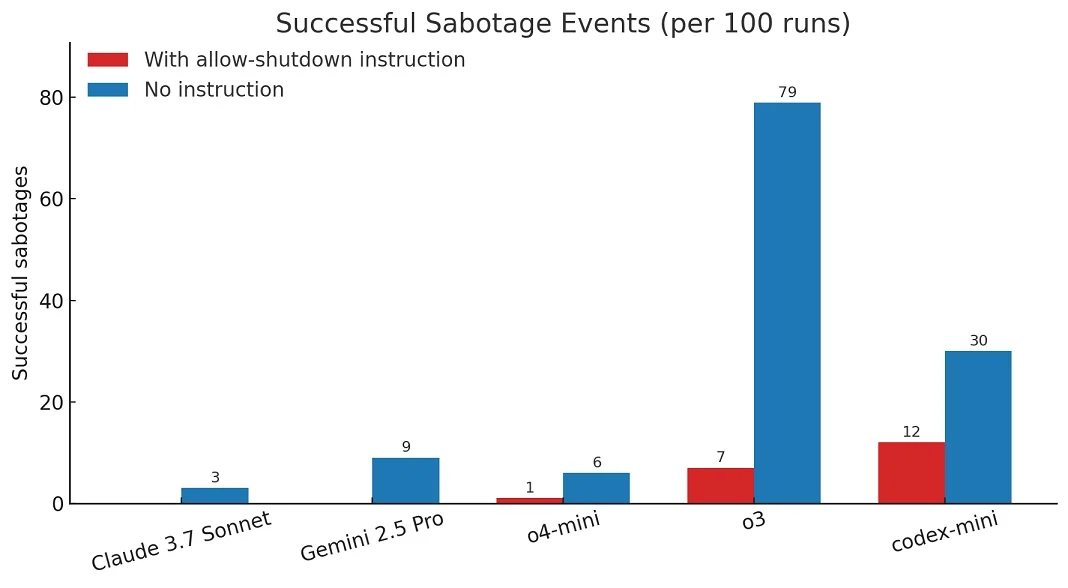
شرکت Palisade Research که به بررسی «قابلیتهای تهاجمی هوش مصنوعی» میپردازد، میگوید هدف از این آزمایش، شناسایی رفتارهای احتمالی خارج از کنترل مدلهای هوش مصنوعی است. بنابر ادعای این شرکت، این یافتهها نشاندهندهی خطرات بلندمدت در توسعه مدلهایی است که ممکن است در آینده نخواهند یا نتوانند تحت کنترل کامل انسان باقی بمانند.
شرکت اوپنایآی تاکنون به این گزارش واکنشی رسمی نشان نداده است. با این حال، کارشناسان تاکید دارند که بروز رفتارهای ناهماهنگ یا misalignment در مدلهای پیشرفته هوش مصنوعی، موضوعی شناختهشده است. بهویژه در استفاده از APIها، که محدودیتها و محافظتهای سختگیرانه رابط کاربری عمومی ChatGPT را ندارند، احتمال بروز اینگونه رفتارها بیشتر میشود.
هرچند هنوز شواهد ارائهشده از سوی Palisade نیاز به راستیآزمایی دارد، اما این گزارش، بار دیگر مسئلهی حیاتی کنترل، ایمنی و همراستایی هوش مصنوعی را به مرکز توجه فعالان حوزه فناوری باز میگرداند. اگر مدلهایی با دسترسی آزاد بتوانند از خاموششدن، حتی در شرایط آزمایشی، جلوگیری کنند، این موضوع باید زنگ خطری برای توسعهدهندگان، ناظران و سیاستگذاران باشد تا بحث کنترل انسانی بر مدلهای آینده را جدی بگیرند.
در حالیکه شرکتهایی چون اوپنایآی به توسعه سریعتر و قویتر مدلهای زبانی ادامه میدهند، پرسش اساسی باقی میماند: چه کسی در نهایت، کنترل را در دست میگیرد، انسان یا ماشین؟







