


وقتی ترس از هوش مصنوعی، خودش به یک تهدید تبدیل میشود
هوش مصنوعی سالهاست مخالفان جدی دارد. از پژوهشگران و دانشمندانی که درباره خطرات آن هشدار…
۲۱ تیر ۱۴۰۵






۲ دی ۱۴۰۳
زمان مطالعه : ۷ دقیقه

بیش از ۵۰ پژوهشگر در یک مطالعه جدیدی به بررسی منبع دادههای هوش مصنوعی پرداختهاند. آنها در این مطالعه سعی داشتند تا منشا احتمالی دادههای هوش مصنوعی یا دادههایی که امکان استفاده از آنها برای آموزش مدلهای مختلف وجود دارد را مشخص کنند. این مطالعه که نشریه فناوری MIT مقالهای درمورد نتایج آن منتشر کرده است به حقایق جالبی درمورد وضعیت فعلی گنجینه دادههای اینترنت اشاره دارد.
به گزارش پیوست، این مطالعه نشان میدهد که با وجود افزایش نفوذ اینترنت در بخشهای مختلف جهان، همچنان دادههای انگلیسی سهم اصلی (۹۰ درصدی) از دادههای اینترنت را در اختیار دارند و ۹۰ درصد دیتاستهای تحت بررسی این پژوهشگران در اروپا و آمریکای شمالی هستند.
همچنین این مطالعه به یک برتری مهم برای گوگل در مدلهای مولد ویدیو اشاره دارد. بررسی پژوهشگران نشان میدهد که پلتفرم یوتیوب مهمترین منبع دادههای مناسب برای آموزش مدلهای ویدیویی است.
گروهی متشکل از ۵۰ پژوهشگر و فعال صنعتی برای مشخص کردن منشا دادههای هوش مصنوعی در پروژهای به نام Data Provenance Initiative به بررسی حدود ۴ هزار دیتاست عمومی در بیش از ۶۰۰ زبان، ۶۷ کشور و سه دهه پرداختند. این بررسی نشان میدهد که منبع این دادهها ۸۰۰ منبع منحصربهفرد و ۷۰۰ سازمان است.
یافتههای این مطالعه به خطر بزرگی درمورد تمرکز قدرت در دست چند شرکت فناوری اشاره میکند.
شاین لانگپر، پژوهشگر MIT که در این پروژه حضور داشته است، میگوید در اوایل دهه ۲۰۱۰، دادهها منابع متعددی داشتند.
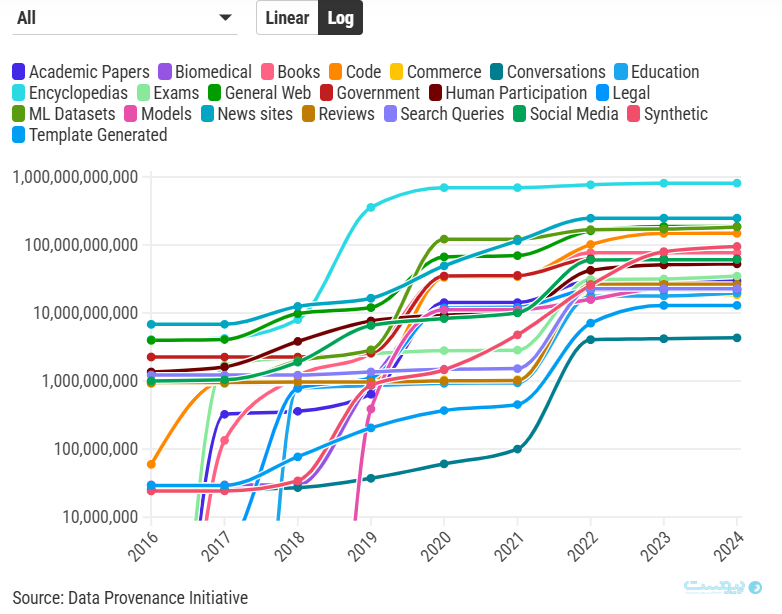
در آن زمان علاوه بر اینترنت و دایرهالمعارفها، منابعی مثل رونوشتها، تماسهای درآمدی و گزارش هوا نیز بخش مهمی از دادهها را تشکیل میدادند. لانگپر میگوید در آن زمان دادههای هوش مصنوعی از منابع مختلفی با ویژگیهای خاص نشات میگرفتند.
در سال ۲۰۱۷ ترنسفورمرها (مبدلها)، زیرساخت اصلی مدلهای بزرگ زبانی، اختراع شدند و صنعت هوش مصنوعی توانست با توسعه مدلهای بزرگ و دیتاستهای بزرگتر، عملکرد ابزارهای هوش مصنوعی را تقویت کند. در حال حاضر بیشتر دیتاستهای هوش مصنوعی براساس محتوای موجود در اینترنت ساخته میشوند. از سال ۲۰۱۸، جهان وب به منبع اصلی دیتاستهای مورد استفاده در تمام رسانهها، از جمله صوت، تصویر و ویدیو تبدیل شده است و شکاف بزرگی را بین دادههای خالص و دادههای تنظیم شده پدید آمده و بزرگتر شده است.
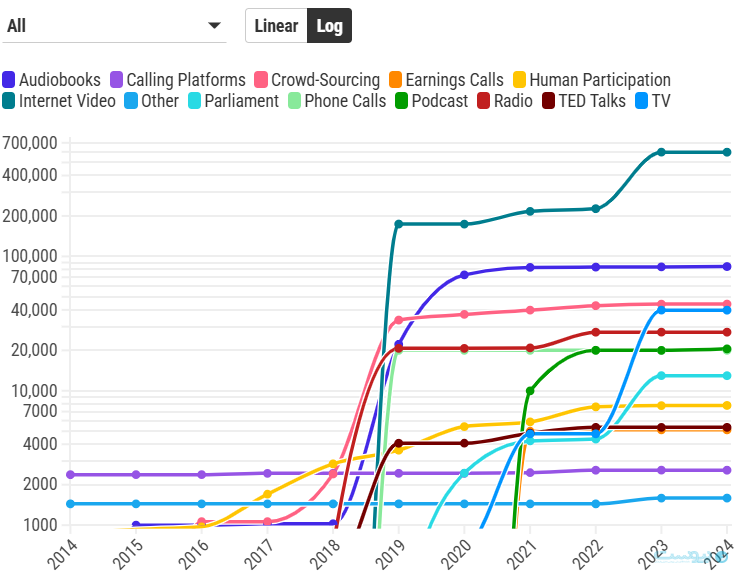
لانگپری میگوید: «در توسعه مدل بنیادی، به نظر هیچ چیزی به اندازه گستره و تنوع داده و وب، برای توانمندیها اهمیت ندارد.» در نتیجه نیاز به داده باعث شده تا استفاده از دادههای مصنوعی نیز افزایش یابد.
در چند سال گذشته ما شاهد توسعه مدلهای چندوجهی بودیم که امکان تولید ویدیو و تصویر را دارند. آنها نیز همانند مدلهای بزرگ زبانی برای بهبود عملکرد خود به دادههای زیادی نیاز دارند و یوتیوب به منبع اصلی دادههای لازم برای این دسته از مدلها تبدیل شده است.
همانطور که در نمودار زیر مشاهده میکنید، بیش از ۷۰ درصد دادههای صوتی و تصویری مورد نیاز برای مدلهای ویدیویی تنها در یک منبع متمرکز شده است.
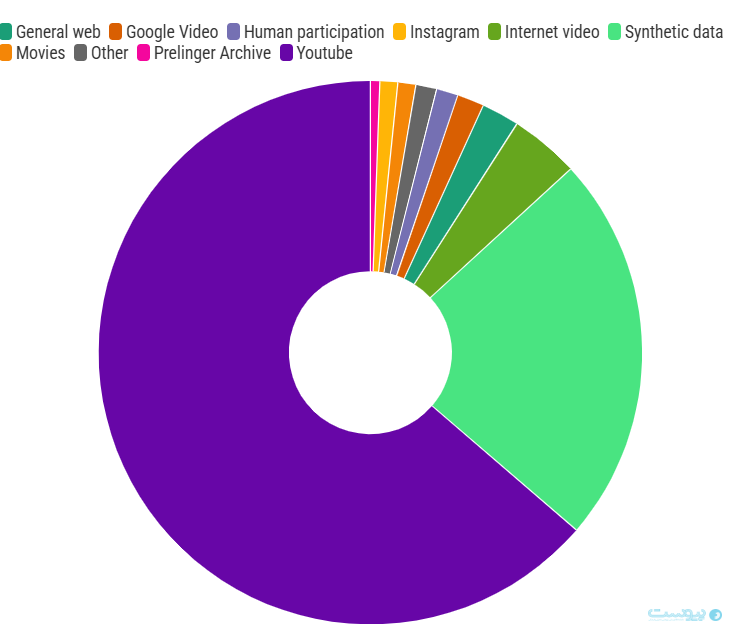
این مساله ممکن است به برتری چشمگیری برای الفابت، شرکت مادر گوگل و مالک یوتیوب، منجر شود. در حوزه دادههای متنی اما شاهد توزیع گستردهتری هستیم و شمار زیادی از وبسایت و پلتفرمهای مختلف را داریم، اما دادههای ویدیویی تا حد زیادی در یک پلتفرم خاص متمرکز شدهاند.
لانگپری میگوید: «این موضوع قدرت متمرکز زیادی را نسبت به بخش زیادی مهمترین دادههای وب در اختیار یک شرکت میگذارد.»
سارا مایرز وست، هممدیر موسسه AI Now میگوید، از آنجایی که گوگل خود در حال توسعه مدلهای هوش مصنوعی، برتری گسترده این شرکت سوالاتی را درمورد نحوه یا احتمال اشتراکگذاری با رقبا پدید آورده است.
میرز وست، میگوید: «خوب است که داده را نه یک منبع طبیعی، بلکه چیزی تصور کنیم که از طریق فرایندهای منحصربهفردی ایجاد میشود.»
او میگوید: «اگر دیتاستهایی که بیشتر هوش مصنوعیهای امروز ما براساس آن هستند، انعکاس انگیزهها و طراحی شرکتهای سودمحور بزرگ باشند-این مساله زیرساخت جهان ما را به انعکاسی از منافع این شرکتهای بزرگ تغییر میدهد.»
سارا هوکر، نایبرئیس بخش تحقیقات شرکت فناوری Cohere،که بخشی از پروژه تحقیقات مذکور است، میگوید چنین حالت متمرکزی همچنین سوالاتی را درمورد نحوه ترسیم تجربه انسان در دیتاستها و نوع مدلها پدید میآورد.
افراد با در نظر گرفتن یک دسته مخاطب خاص ویدیوهای خود را در یوتیوب بارگذاری میکنند و رفتار مردم در این ویدیوها معمولا با هدفی خاص تنظیم شده است. هوکر میگوید: «آیا [این دادهها] تمام ریزهکاریهای بشریت و تمام حالتهای مختلف موجودیت ما را پوشش میدهد؟»
شرکتهای هوش مصنوعی معمولا دادههایی که برای آموزش مدلهای خود استفاده میکنند را به اشتراک نمیگذارند. یکی از دلایل این کار محافظت از برتری رقابتی است. دلیل دیگر آنهم پیچیدگی و ابهام دستهبندی و توزیع دیتاستها است و این شرکتها معمولا منشا اصلی تمام دادهها را نمیدانند.
همچنین این شرکتها احتمالا اطلاعات کاملی درمورد محدودیتهای استفاده یا اشتراکگذاری این دادهها ندارند. پژوهشگران Data Provenance Initiative دریافتند که دیتاستها معمولا به واسطه شروط استفاده یا جواز محدود میشود که درنتیجه استفاده از آنها را برای اهداف مثل استفاده تجاری محدود کند.
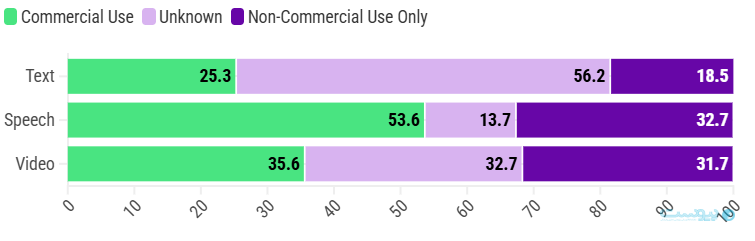
هوکر میگوید: «عدم پیوستگی در سطربندی دادهها باعث شده تا توسعه دهندگان به سختی بتوانند درمورد دادههایی که باید استفاده کنند تصمیم درستی بگیرند.»
همچنین به گفته لانگپری، اطمینان از اینکه مدل شما براساس دادههای دارای حق کپیرایت آموزش ندیده باشد، تقریبا غیرممکن است.
شرکتهای هوش مصنوعی از جمله اوپنایآی و گوگل به تازگی قراردادهایی با ناشران، فریومهای بزرگ مثل ردیت و پلتفرمهای شبکه اجتماعی به امضا رساندهآند. اما این هم راهکار دیگری برای تمرکز قدرت محسوب میشود.
لانگپری میگوید: «این قراردادهای انحصاری ممکن است اینترنت را به چندین قسمت از دسترسی مجاز و غیرمجاز تقسیم کند.»
این روند به نفع بزرگترین بازیگران هوش مصنوعی است امکان انعقاد چنین قراردادهایی را دارند و به زیان پژوهشگران، شرکتهای خیره و شرکتهای کوچکتری که در دسترسی به این دادهها به مشکل میخورند. بزرگترین شرکتّا بهترین منابع را برای کشت داده در اختیار دارند.
لانگپری میگوید: «این موج جدیدی از دسترسی نامتقارن است که تا به حال به این اندازه در وب آزاد مشاهده نکردیم.»
دادههای مورد استفاده برای آموزش مدلهای هوش مصنوعی عمدتا از جهان غرب منشا میگیرند. بیش از ۹۰ درصد از دیتاستهایی که پژوهشگران در این مطالعه بررسی کردند مربوط به اروپا و آمریکای شمالی است و تنها ۴ درصد آنها از آفریقا میآیند.
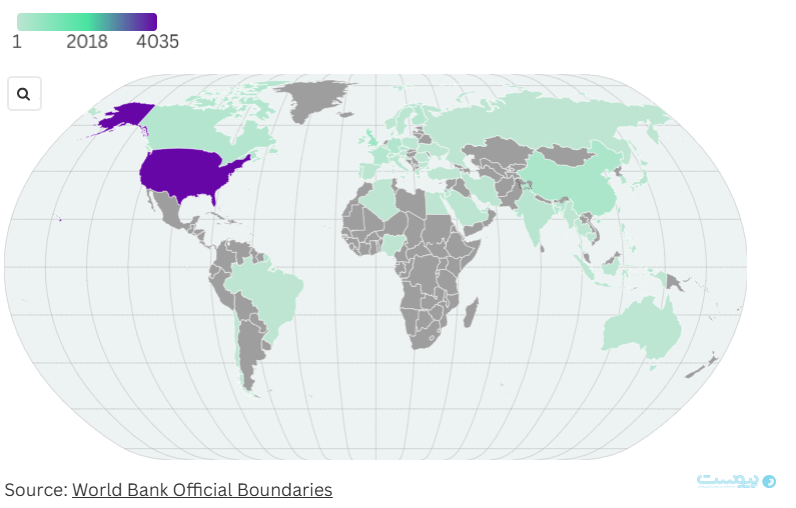
هوکر میگوید: «این دیتاستها یک بخش از جهان ما و فرهنگ ما را منعکس میکنند، اما دیگران را نادیده میگیرند.»
گیادا پیستیلی، کردارشناس ارشد شرکت هوش مصنوعی Hugging Face، که البته نقشی در این تحقیقات نداشته است، میگوید جایگاه مسلط زبان انگلیسی در دادههای آموزشی را میتوان ناشی از آن دانست که همچنان بیش از ۹۰ درصد اینترنت به زبان انگلیسی است و در حال حاضر هنوز جاهای زیادی از زمین اینترنت ضعیفی دارند یا اصلا به اینترنت دسترسی ندارند. اما دلیل دیگر آن نیز آسودگی است زیرا گردآوری دیتاست به دیگر زبانها و در نظر گرفتن دیگر فرهنگها، انگیزه واقعی و تلاش بسیاری را میطلبد.
تمرکز این دادهها بر جهان غرب را به ویژه در مدلهای چندوجهی میتوان مشاهده کرد. برای مثال وقتی از یک مدل هوش مصنوعی میخواهیم تا تصویری از یک عروسی را ترسیم کند، تنها نمایی از عروسیهای غربی را دریافت میکنیم زیرا بیشتر دیتاست آموزشی این مدل براساس دادههای غربی است.
افزایش این سوگیریها ممکن است به یک جهانبینی متمرکز بر ایالات متحده منتهی شود و دیگر زبانها و فرهنگها از آن حذف شوند.
هوکر میگوید: «ما در سراسر جهان از این مدلها استفاده میکنیم و تفاوت بسیاری بین جهانی که ما میبینیم و جهانی که این مدلها میبینند وجود دارد.»







