


وقتی ترس از هوش مصنوعی، خودش به یک تهدید تبدیل میشود
هوش مصنوعی سالهاست مخالفان جدی دارد. از پژوهشگران و دانشمندانی که درباره خطرات آن هشدار…
۲۱ تیر ۱۴۰۵






۱۵ آبان ۱۴۰۳
زمان مطالعه : ۶ دقیقه

گزارش جدیدی از شرکت ارائه دهنده هوش مصنوعی Appen درمورد وضعیت این فناوری نشان میدهد که شرکتها در دسترسی به دادههای با کیفیت مورد نیاز برای سیستمهای هوش مصنوعی به مشکل خوردهاند. این در حالی است که استفاده از این فناوری در عملیاتهای تجاری بیشتر شده است.
به گزارش پیوست به نقل از ونچربیت، گزارش وضعیت هوش مصنوعی ۲۰۲۴ از شرکت Appen که با نظرسنجی از ۵۰۰ تصمیمگیرنده IT در آمریکا گردآوری شده نشان میدهد که استفاده از هوش مصنوعی در یک سال گذشته ۱۷ درصد بیشتر شده است اما سازمانها با موانع بزرگی برای آمادهسازی داده و تضمین کیفیت آن روبرو هستند. این گزارش نشان از یک رشد ۱۰ درصدی در موانع مربوط به تامین منبع، پاکسازی و نشانهگذاری داده دارد که به پیچیدگیهای ساخت و نگهداری از ابزارهای مفید هوش مصنوعی اشاره دارد.
سی چن، رئیس استراتژی Appen، در مصاحبهای تصریح کرد که «در حالی که مدلهای هوش مصنوعی با مسائل پیچیده و تخصصیتر دست و پنجه نرم میکنند، پیشنیازهای داده نیز تغییر میکند. شرکتهای به این نتیجه رسیدهاند که داشتن مقدار زیادی داده دیگر به تنهایی کافی نیست. برای تقویت یک مدل، داده باید بسیار با کیفیت باشد که به معنی دقت، تنوع، نشانگذاری درست و تنظیم آن برای کاربردهای ویژه هوش مصنوعی است.»
در حالی که پتانسیل هوش مصنوعی همچنان در حال رشد است، این گزارش چندین حوزه کلیدی از موانع شرکتی را شناسایی کرده است. در ادامه متن پنج نکته مهم از گزارش هوش مصنوعی Appen را بررسی میکنیم.
به لطف پیشرفت مدلهای بزرگ زبانی که امکان خودکارسازی وظایف مختلف را برای سازمانها و کسبوکارها فراهم میکند، استفاده از هوش مصنوعی با نرخ قابل توجه ۱۷ درصدی در سال ۲۰۲۴ بیشتر شده است. شرکتها در حوزههای مختلفی از عملیاتهای IT گرفته تا تحقیق و توسعه از هوش مصنوعی مولد برای تسهیل فرایندهای داخلی و بهبود بهرهوری استفاده میکنند. اما افزایش استفاده از هوش مصنوعی مولد باعث ایجاد موانع تازهای به ویژه در بحث مدیریت داده شده است.
چن میگوید: «خروجیهای هوش مصنوعی مولد متنوعتر، غیرقابل پیشبنی و وابسته به تحلیل هستند که تعریف و سنجش موفقیت آن را سختتر می کند. مدلها برای رسیدن به سطح آمادگی لازم برای استفاده شرکتی باید با دادههای با کیفیت و مناسب برای کاربردهای خاص تقویت شوند.»
یکی از روشهای اصلی تامین دادههای آموزشی، جمعآوری داده شخصی سازی شده سات که نشان از تغییر رویکرد پیشین نسبت به جمعآوری دادههای عمومی است و در حال حاضر بیشتر شرکتها به سراغ دیتاستهای شخصیسازی شده میروند.

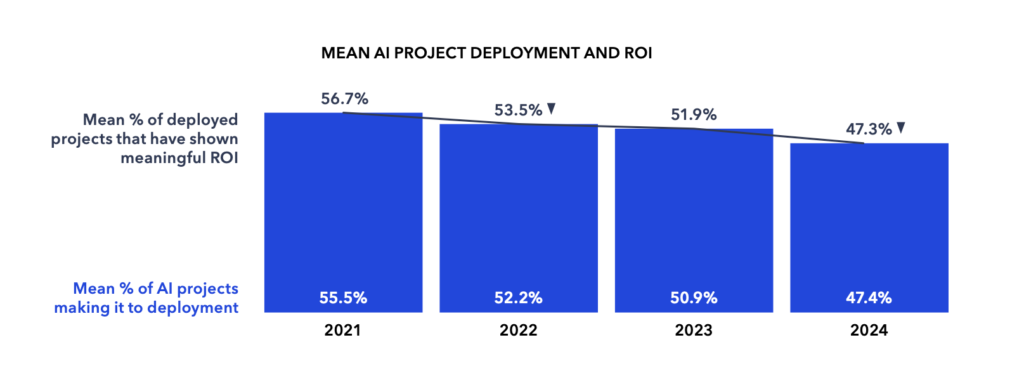
با وجود اشتیاق بیسابقه درمورد هوش مصنوعی، این گزارش از یک جریان نگرانکننده حکایت میکند: پروژههای هوش مصنوعی که به استفاده نهایی میرسند تعداد کمی دارند و حتی آنهایی که به مرحله استفاده نهایی میرسند هم بازده سرمایهگذاری یا ROI پایینی دارند. از سال ۲۰۲۱× میانگین پروژههایی که به مرحله استفاده نهایی رسیدهاند با نرخ ۸.۱ درصد کاهش یافته و در عین حال نرخ پروژههایی که در مرحله اجرا بازده سرمایه معناداری دارند هم ۹.۴ درصد کمتر شده است.
این سقوط ناشی از افزایش پیچیدگی مدلهای هوش مصنوعی است. کاربردهای ساده مثل تشخیص تصویر و خودکارسازی گفتار در حال حاضر به بلوغ رسیدهاند اما شرکتها به سمت طرحهای بلندپروازانهتری مثل هوش مصنوعی مولد میورند که نیازمند دادههای با کیفیت و شخصی سازی شده است و اجرای آنها دشوارتر از نمونههای ساده است.
چن میگوید: «هوش مصنوعی مولد در درک، استدلال و تولید محتوا قابلیتهای پیشرفتهتری دارد اما اجرایی کردن این فناوریها ذاتا دشوار است.»
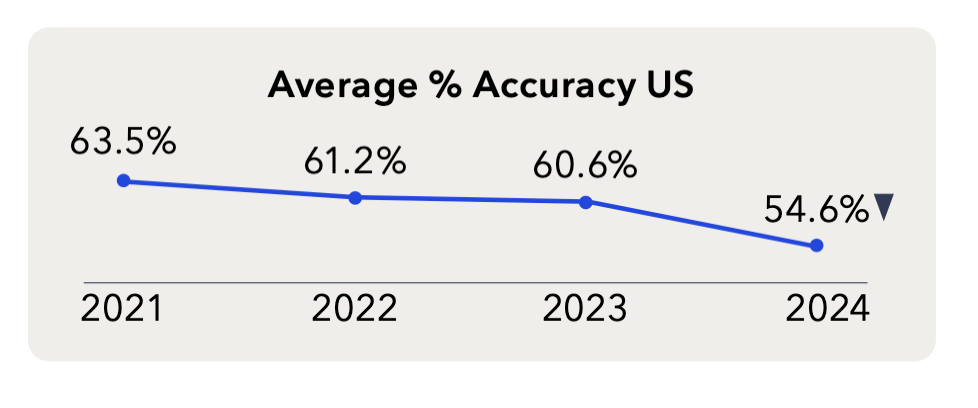
این گزارش به یک مشکل اساسی برای استفاده از هوش مصنوعی اشاره میکند: دقت داده از سال ۲۰۲۱حدود ۹ درصد کاهش یافته است. در حالی که مدلهای هوش مصنوعی پیچیدهتر میشوند، داده مورد نیاز آنها نیز پیچیدهتر میشود و نیازمند تفسیرهای تخصصی و با کیفیت است.
نرخ خیرهکننده ۸۶ درصدی از شرکتها در هر سه ماهه هوش مصنوعی خود را احیا یا بروزرسانی میکنند که به لزوم دادههای مرتبط و تازه اشاره دارد. با این حال، افزایش نرخ بروزرسانیها باعث شده تا تضمین دقت و تنوع دادهها سختتر شود. شرکتها برای تامین تقاضای خود به سراغ ارائهدهندگان شخص ثالث داده میروند و حدود ۹۰ درصد از کسبوکارها برای آموزش و ارزیابی مدلها خود وابسته به منابع خارجی هستند.
چن میگوید: «با اینکه نمیتوان آینده را پیشبینی کرد، تحقیقات ما نشان میدهد که مدیریت کیفیت داده به مشکل بزرگی برای شرکتها تبدیل میشود. با توجه به پیچیدگی بیشتر مدلهای هوش مصنوعی مولد، تامین، پاکسازی و نشانهگذاری داده حتی همین امروز هم به یک مانع کلیدی تبدیل شده است.»
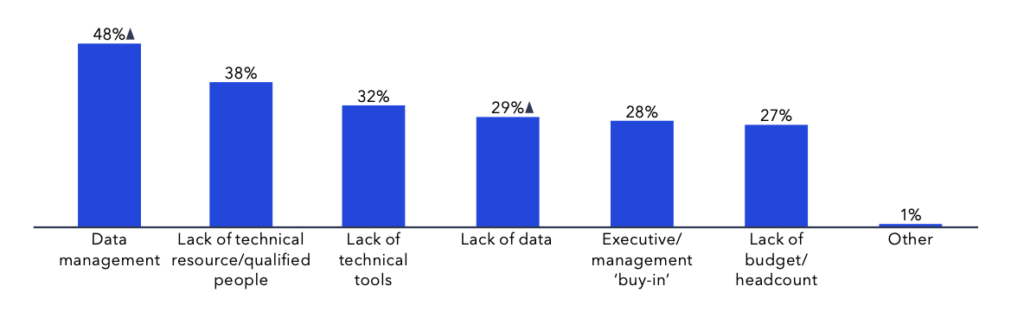
گزارش Appen نشان میدهد که بنبست و تنگناهای مربوط به تامین، پاکسازی و نشانگذاری داده با نرخ ۱۰ درصد در سال در حال افزایش است. این تنگناها و بنبستها به طور مستقیم بر اجرای موفق پروژههای هوش مصنوعی تاثیرگذارند. هرچه کاربردهای هوش مصنوعی تخصصیتر میشود، چالش تامین و آمادهسازی دادههای خاص نیز سختتر می شود.
چن میگوید: «مشکلات آمادهسازی داده افزایش یافته است. ماهیت تخصصی این مدلها باعث الزام دیتاستهای تخصصی شده است.»
شرکتها برای رفع این مشکلات به استراتژیهای بلندمدتی روی آوردهاند که بر دقت، پایداری و تنوع داده تاکید دارد. بسیاری از شرکتها همچنین به دنبال همکاری استراتژی با ارائه دهندگان داده هستند.
در حالی که پیشرفت هوش مصنوعی با سرعت ادامه دارد، اما نقش انسان در این میان بیش از پیش افزایش یافته است. این گزارش نشان میدهد که ۸۰ درصد از پاسخ دهندگان به اهمیت حضور انسان در حلقه یادگیری ماشینی تاکید دارند. براساس این فرایند، از انسانها برای راهنمایی و بهبود مدلهای هوش مصنوعی استفاده میشود.
چن میگوید: «مداخله انسانی همچنان برای توسعه سیستمهای هوش مصنوعی با بازدهی بالا،اخلاقی و مرتبط نقش اساسی دارد.»
متخصصان انسانی به ویژه برای جلوگیری از سوگیری و موضوعات اخلاقی اهمیت دارند. انسانها با دانش خاص و شناسایی سوگیریهای موجود در خروجی هوش مصنوعی به اصلاح و همسویی مدلها با رفتار و ارزشهای جهان واقعی کمک میکنند. این مساله به ویژه برای هوش مصنوعی مولد که خروجی آن غیرقابل پیشبینی است و به نظارت نیاز دارد از اهمیت بالایی برخوردار است.







