


وقتی ترس از هوش مصنوعی، خودش به یک تهدید تبدیل میشود
هوش مصنوعی سالهاست مخالفان جدی دارد. از پژوهشگران و دانشمندانی که درباره خطرات آن هشدار…
۲۱ تیر ۱۴۰۵






۲۱ مهر ۱۴۰۳
زمان مطالعه : ۶ دقیقه

مدلهای بزرگ زبانی که پنجره محتوایی طولانی دارند به تازگی توجه بسیاری را به خود جلب کردند. توان پردازش صدها هزار یا حتی میلیونها توکن در یک پرامپت باعث ایجاد فرصتهای زیادی برای توسعه دهندگان شده است. اما این LLMها در درک و استفاده از این اطلاعات طولانی چطور عمل میکنند؟
به گزارش پیوست به نقل از ونچربیت، پژوهشگران گوگل دیپمایند از سنجه جدیدی به نام مایکلانجلو رونمایی کردهاند که قرار است توانمندی استدلال LLMها در محتوای طولانی را بررسی کند. یافتههای آنها که در یک مقاله تحقیقاتی جدید منتشر شد نشان میدهد با اینکه مدلهای پیشتاز در استخراج اطلاعات از دادههای موجود در درون متنهای بزرگ پیشرفت کردهاند، اما هنوز در کارهایی که نیازمند استدلال درمورد ساختار داده است با مشکل مواجه هستند.
پیدایش LLMهایی که پنجره محتوایی طولانی دارند و از ۱۲۸ تا یک میلیون توکن را پردازش میکنند، باعث شد تا پژوهشگران به دنبال سنجههای تازهای برای ارزیابی توانمندیهای آنها باشند. با این حال بیشتر تمرکز روی وظایف استخراج از محتوا است و در مشهورترین آنها «سوزن در انبار کاه»، مدل مورد نظر وظیفه مییابد تا اطلاعات مشخصی را در یک محتوای طولانی یافته و استخراج کند.
کیران ودراهیلی، پژوهشگر ارشد گوگل دیپمایند، میگوید: «به مرور زمان، مدلها عملکرد بسیار بهتری در محتوای طولانی پیدا کردهاند. برای مثال ارزیابی سوزن در انبار کاه در محتواهای بسیار طولانی هم تا بهترین حد پیش رفته است. بنابراین، حالا باید مشخص کرد که آیا مدلها میتوانند در متنهای طولانی، کارهای سختتری که در متنهای کوتاه انجام میدهند را تکرار کنند.»
وظایف استخراجی لزوما نشانگر توانمندی استدلال مدل در محتوای طولانی نیست. یک مدل شاید بتواند بدون درک رابطه بین بخشهای مختلف متن، یک قطعه اطلاعات مشخص را اسختراج کند. در عین حال، سنجههای موجود که توان استدلال مدل در محتواهای طولانی را ارزیابی میکنند، محدودیتهایی دارند.
ودراهیلی میگوید: «به سادگی میتوان ارزیابیهایی برای استدلال متن طولانی طراحی کرد که با ترکیبی از استخراج و اطلاعات ذخیره شده در مدل حل میشوند، در نتیجه آزمون تونایی مدل در استفاده از محتوای بلند را اتصال کوتاه داد.»
پژوهشگران برای رفع محدودیتهای موجود در سنجههای فعلی، از مایکلانجلو رونمایی کردند که یک «ارزیابی مینیمال، مصنوعی و فاشنشده برای استدلال مدلهای بزرگ زبانی در محتوای طولانی است.»
مایکلانجلو بر اساس این طراحی شده است که مجسمه سال با تراشیدن بخشهای نامربوط، ساختار موجود در قلب سنگ را به نمایش میگذارد. این سنجه روی ارزیابی توانایی مدل در درک روابط و ساختار اطلاعات در داخل پنجره محتوایی تمرکز میکند و تنها محدود به استخراج یک سری حقایق نیست.
این سنجه از سه وظیفه اساسی تشکیل میشود:
لیست پنهان: این مدل باید یک زنجیره طولانی از عملیاتها که روی یک لیست پایتون اعمال شده را پردازش، بیانیههای اضافی یا نامرتبط را حذف و بیانیه نهایی لیست را مشخص کند. پژوهشگران مینویسند: «لیست پنهان در واقع توانایی یک مدل در ردیابی مشخصههای پنهان ساختار داده در طول یک زنجیره کد را مورد سنجش قرار میدهد.»
تجزیه چندمرحلهای با ارجاع متقابل (MRCR): مدل مورد نظر باید بخشهایی از یک مکالمه طولانی بین کاربر و یک LLM را تولید کنند. برای این کار مدل باید ساختار مکالمه مورد نظر را شناخته و ارجاع به قبل را حتی در صورتی که مکالمه حاوی عناصر گمراهکننده باشد، درک کند. پژوهشگران مینویسند: «MRCR توانایی مدل در درک ترتیببندی متن طبیعی برای تفکیک پیشنویسهای مشابه از یک نوشته واحد و بازتولید بخش مشخصی از محتوای پیشین در پاسخ به سوالات دشوار را مورد سنجش قرار میدهد.»
سنجه «نمیدانم» (IDK): پس از ارائه یک داستان طولانی، از مدل خواسته میشود تا به سوالات چندگزینهای پاسخ دهد. محتوا پاسخ برخی از سوالات را در خود ندارد و مدل باید بتواند سرحد دانش خود را تشخیص داده و با عبارت «نمیدانم» پاسخ دهد. پژوهشگران مینویسند: «سنجه IDK، توانایی مدل در تشخیص اینکه آیا براساس محتوای موجود میداند یا نمیداند را مورد سنجش قرار میدهد.»
وظایف موجود در سنجه مایکلانجلو مبتنی بر یک چارچوب نوین به نام پرسشهایی با ساختار نهفته (LSQ) هستند. LSQ یک رویکرد کلی برای طراحی ارزیابیهای استدلال در محتوای طولانی است که میتوان آن را با طول مشخصی تنظیم کرد. این رویکرد میتواند به جای استخراج حقایق، درک مدل از اطلاعات پنهان را نیز ارزیابی کند. LSQ با ساخت مصنوعی دادههای آزمایش، از درز اطلاعات به داخل دادههای آموزشی نیز جلوگیری میکند.
پژوهشگران مینویسند: «با درخواست از مدل برای استخراج ساختارها به جای مقدار (مجسمهای از سنگ به جای سوزن از انبار کاه)، ما میتوانیم به جای قدرت اسختراج، درک محتوایی مدل زبانی را بررسی کنیم.»
LSQ سه تفاوت کلیدی با دیگر رویکردهای ارزیابی دارد. اول اینکه به طور ویژه برای اجتناب از مشکلات اتصال کوتاه در ارزیابیهایی طراحی شده که میخواهند فراتر از وظایف استخراج اطلاعات باشند. دوم، این رویکرد روشی را برای افزایش پیچیدگی و طول محتوا به صورت مستقل ارائه میکند و در نهایت به اندازه کافی عمومیت دارد که طیف وسیعی از وظایف استدلالی را تحت پوشش بگیرد. سه آزمونی که در سنجه مایکلانجلو استفاده میشوند، برداشت و استدلال را در محتوایی که به سادگی نوشته شده پوشش میدهند.
ودراهیلی میگوید: «هدف این است که ارزیابیهای محتوای طولانی و فراتر از استدلال با پیروی از LSQ باعث شوند تا در موارد کمتری یک ارزیابی پیشنهاد تنها به یک وظیفه استخراجی بدل شود.»
پژوهشگران ۱۰ مدل زبانی پیشتاز را براساس مایکلانجلو ارزیابی کردهاند که در این بین مدلهایی مثل جمنای، GPT-4 و 4.o و Claude نیز حضور دارند. آنها این مدلها را با سرحد یک میلیون توکن مورد ارزیابی قرار دادند. مدلهای جمنای بهترین عملکرد را در MRCR داشتند، GPT عملکرد بهتری در لیست پنهان داشت و Cloude 3.5 Sonnet نیز بالاترین نمره را در IDK دریافت کرد.
با این حال نمره تمامی مدلها با افزایش پیچیدگی وظایف استدلالی به شکل قابل توجهی کاهش یافت که نشان میدهد مدلهای زبانی امروزی حتی با پنجرههای محتوای طولانی هم جای زیادی برای پیشرفت دارند.
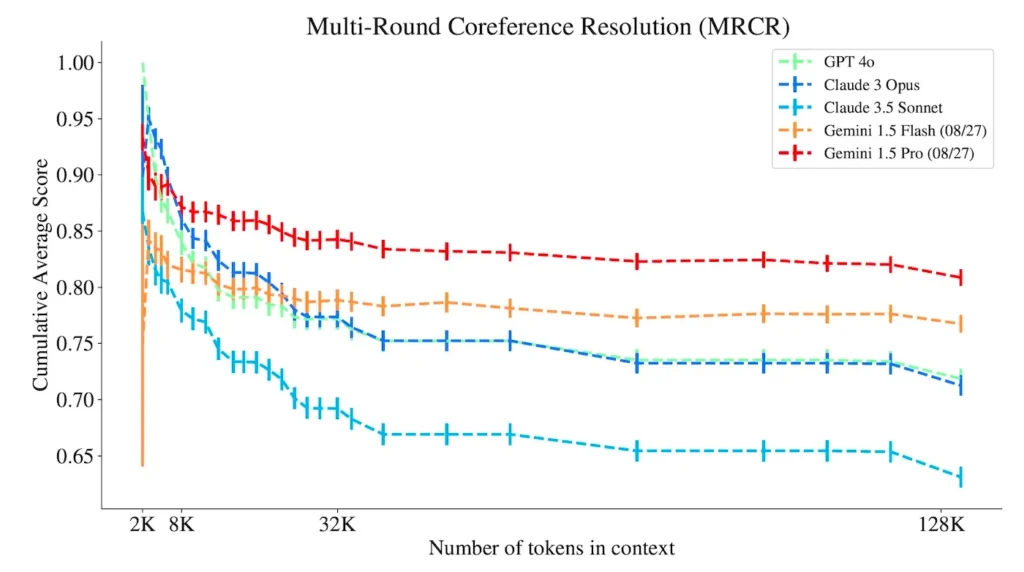
ودراهیلی میگوید: «مدلهای پیشتاز در تمام شاخصهای استدلال فراتر از استخراج (لیست پنهان، MRCR و IDK) که در مایکلانجلو بررسی کردیم جای پیشرفت دارند. نقاط ضعف و قوت مدلهای مختلف متفاوت است- هر دسته عملکرد متفاوتی در طول محتویای متفاوت و وظایف مختلف دارد. اما وجه مشترک تمامی مدلها، تضعیف عملکرد آنها در وظایف استدلال طولانی است.»
پژوهشگران معتقدند که وقتی مدل باید از بخشهای مختلف یک محتوای طولانی برای استدلال خود استفاده کند و امکان اتکا به دادههای آموزشی برای آن وجود ندارد، عملکرد آن به شکل قابل توجهی با افزایش طول محتوا تضعیف میشود.







