
علم پشت پرده ویرال شدن محتوا چیست
ویرال شدن یک محتوا فقط شانس یا اتفاق نیست و قطعاً تصادفی رخ نمیدهد. دلیلی…
۱۵ فروردین ۱۴۰۴






سینا حسنزاده
۱ خرداد ۱۴۰۲
زمان مطالعه : ۸ دقیقه
در این مطلب میخوانید
یادگیری ماشین یکی از دستاوردهای هوش مصنوعی است که تاثیرات بسیاری را در زندگی انسانها بهوجود آورده است. این یادگیری در دو نوع با نظارت و بدون نظارت تعریف میشود. یادگیری ماشین بدون نظارت شامل الگوریتمهایی است که نیازی به نظارت ندارد و میتوان به راحتی توسط این فناوری کارهای سخت و پیچیده را انجام داد و به نتیجه رساند.
یادگیری بدون نظارت یا Unsupervised learning نوعی یادگیری ماشین است که کاربران لازم نیست بر مدل آن نظارت کنند. در عوض، مدل کنونی روی خود کار میکند تا الگوها و اطلاعات شناسایی نشده را کشف کند. اغلب کار این مدل با دادههای برچسبنخورده است.
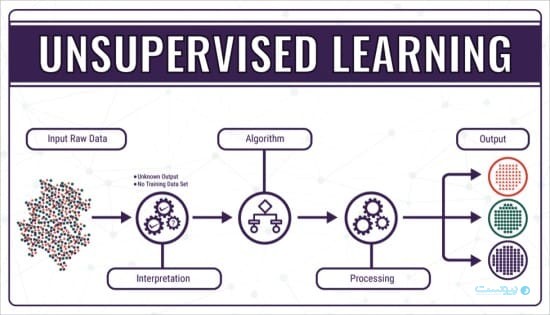
کاربران با استفاده از الگوریتمهای یادگیری بدون نظارت میتوانند کارهایی با پردازش پیچیدهتر را در مقایسه با یادگیری با نظارت انجام دهند. گرچه که یادگیری بدون نظارت نسبت به دیگر شیوههای یادگیری طبیعی پیشبینیناپذیرتر است. الگوریتمهای یادگیری بدون نظارت شامل خوشهبندی، شناسایی ناهنجاری، شبکههای عصبی و غیره میشود.
برای درک بهتر و بیشتر با این مثال به توضیح یادگیری ماشین بدون نظارت میپردازیم. یک نوزاد برای اینکه سگ خانهای خودشان را بشناسد و در ذهنش بماند مدتی این سگ را میبیند و با ظاهر و حرکاتش آشنا میشود. مدتی بعد یک سگ جدید را مشاهده میکند. این سگ سعی میکند با نوزاد بازی کند و با او ارتباط برقرار کند. نوزاد برای اولین بار است که این سگ جدیدرا میبیند، با این حال او ویژگیهای زیادی را تشخیص میدهد؛ از جمله ۲ گوش، ۲ چشم و راه رفتن با دست و پا که مشابع سگ خانهای خودشان است. بنابراین نوزاد این حیوان جدید را که شباهت بسیار زیادی به سگ خانهای خودشان دارد به عنوان سگ شناسایی میکند.
مثال بالا نوعی یادگیری بدون نظارت بهشمار میرود. در این مثال، به نوزاد چیزی آموزش داده نشده، اما از روی دادهها (مشخصات سگ خانهای خودشان) یاد میگیرد. اگر شخصی به نوزاد درباره حیوان جدید توضیح میداد که سگ است، شیوه یادگیری به Supervised یا بانظارت تغییر پیدا میکرد.
اصلیترین دلایل استفاده از یادگیری بدون نظارت در یادگیری ماشین شامل موارد زیر میشود:
در زیر، انواع خوشهبندی الگوریتمهای یادگیری ماشین بدون نظارت را میبینید. مشکلات یادگیری بدون نظارت به دو گروه مشکلات خوشهبندی و اتحاد تقسیم میشوند.
خوشهبندی یکی از مفاهیم پراهمیت در حوزه یادگیری بدون نظارت است. این مفهوم بیشتر با پیداکردن ساختار و الگو در مجموعهای از دادههای دستهبندی نشده کار دارد. الگوریتمهای خوشهبندی یادگیری بدون نظارت، دادههای شما را پردازش کرده و در صورت وجود خوشههای (گروهها) طبیعی، آنها را پیدا میکند. همچنین، میتوانید تعداد خوشههایی را که الگوریتمهای شما باید آن را پیدا کنند، تغییر دهید. خوشهبندی انواع مختلفی دارد که میتوان آنها را بهکار گرفت.
خوشهبندی درختی، الگوریتمی است که سلسله مراتبی از خوشهها را میسازد. این نوع خوشهبندی با دادهای شروع میشود که به خوشه خودش ضمیمه شده است. در خوشهبندی درختی، دو خوشه نزدیک به هم در یک خوشه قرار میگیرند. الگوریتم زمانی تمام میشود که تنها یک خوشه باقی ماندهباشد.
K-means الگوریتم خوشهبندی تکرارشوندهای است که به یافتن بیشترین مقدار برای هر تکرار کمک میکند. ابتدا تعداد خوشهها را انتخاب میکنیم. شما باید نقاط داده را در این روش به گروههای K خوشهبندی کنید. K بزرگتر یعنی گروههای کوچکتر با جزئیات بیشتر و K کوچکتر یعنی گروههای بزرگتر با جزئیات کمتر.
خروجی الگوریتم، گروهی از برچسبهاست. هر گروه در خوشهبندی K-means با ایجاد نقطه مرکزی برای هر خوشه تعریف میشود. نقاط مرکزی قلب هر خوشه هستند که نزدیکترین نقاط به خود را جذب و به خوشه اضافه میکنند.
تعداد خوشههای این نوع از خوشهبندی K-means در ابتدا ثابت است. همه دادهها به تعداد خوشههای ثابتی اختصاص داده میشود. در این روش به شماره خوشههای K به عنوان ورودی نیازی نداریم. فرآیند تجمعی با شکلدادن هر داده به خوشه تکی آغاز میشود.
خوشهبندی تجمعی از طریق ادغام فرآیندها و با استفاده از اندازهگیری مسافت، تعداد خوشهها (یکی در هر تکرار) را کاهش میدهد. در نهایت، یک خوشه بزرگ وجود دارد که تمام مدلها را در بر میگیرد.
هر سطح در خوشهبندی دندروگرام نماینده خوشهای امکانپذیر است. ارتفاع دندروگرام نشاندهنده سطح شباهت بین دو خوشه پیوندی است. خوشهها هرچه نزدیکتر به پایین فرآیند باشند، به خوشهای شباهت بیشتری دارند که در حال یافتن گروهی از دندروگرامی است که غیرطبیعی و ذهنی است.
نزدیکترین همسایه K، سادهترین مرتبکننده در حوزه یادگیری ماشین است. KNN با بقیه روشها تفاوت دارد که یکی از آنها عدم تولید هیچگونه مدلی است. الگوریتم ساده این بخش، همه موارد در دسترس را ذخیره کرده و براساس معیار شباهت، دستهبندی میکند.
زمانی که بین مثالها فاصله باشد، این روش به خوبی جواب میدهد. اگر مجموعه داده بزرگ و محاسبات فواصل پیچیده باشد، سرعت یادگیری پایین میآید.
آنالیز اجزای اصلی زمانی بهدردتان میخورد که فضایی با ابعاد بالاتر بخواهید. شما باید مبنایی برای آن فضا انتخاب کنید و تنها ۲۰۰ مورد مهم آن را مبنا قرار دهید. به این مبنا، جزء اصلی میگویند. زیرمجموعهای که از ترکیب آن انتخاب میکنید، فضای جدیدی بهشمار میرود که نسبت به فضای اصلی کوچکتر است. بدین ترتیب، پیچیدگی دادهها تا حد امکان حفظ میشود.
دادهها در این روش به شکلی گروهبندی میشوند که هر داده تنها متعلق به یک گروه است.
مثال: K-means
هر داده در این روش یک خوشه محسوب میشود. واحدهای تکرارشونده بین دو خوشه نزدیک، تعداد خوشهها را کاهش میدهد.
مثال: Hierarchical Clustering
ما در این روش از مجموعههای مبهم برای خوشهبندی دادهها استفاده میکنیم. هر نقطه به دو یا چند خوشه با سطح عضویت متفاوت تعلق دارد. در این روش، هر داده با مقدار مناسب عضویت خود مرتبط میشود.
مثال: C-mean
ما در این روش از توزیع احتمالی برای ایجاد خوشهها بهره میبریم.
مثال: کلمات کلیدی زیر:
قوانین اتحاد، مجوزی برای برقرار ارتباط بین مدلهای داده در پایگاههای داده بزرگ است. روش بدون نظارت اتحاد به دنبال کشف ارتباطی جالب بین متغیرهای دیتابیسی بزرگ است. برای مثال، افرادی که خانه جدید میخرند، احتمالا علاقهمند به خرید اسباب اثاثیه جدید نیز هستند.
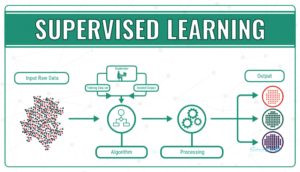
تفاوتهای اصلی بین یادگیری ماشین بدون نظارت و با نظارت به شرح زیر است:
| پارامترها | تکنیک یادگیری ماشین با نظارت | تکنیک یادگیری ماشین بدون نظارت |
| داده ورودی | الگوریتمها با استفاده از داده برچسبخورده آموزش میبینند | الگوریتمها در برابر دادههایی استفاده میشوند که برچسب نخوردهاند. |
| پیچیدگی محاسباتی | یادگیری با نظارت روش سادهتری است | یادگیری بدون نظارت از لحاظ محاسباتی پیچیدهتر است |
| دقت | دقت بالا و روشی مطمئن | روشی با دقت و اطمینان کمتر |
برخی از برنامههای یادگیری ماشین بدون نظارت عبارتند از:






