


پژوهش ایسپا: ۷۴ درصد کاربران از فیلترشکن استفاده میکنند
استفاده گسترده از فیلترشکن، مخالفت با قطع اینترنت و افزایش نارضایتی کاربران، سه محور اصلی…
۳۰ تیر ۱۴۰۵






۱۱ آبان ۱۴۰۴
زمان مطالعه : ۷ دقیقه
ظهور نسل جدید مرورگرهای هوش مصنوعی مانند اطلس (Atlas) از اوپنایآی و مرورگر کامت (Comet) از شرکت Perplexity، تجربه متفاوتی از مرور وب را برای کاربران رقم زده است و با اینکه همچنان مرورگرهای سنتی عمده ترافیک وب را در خود جای میدهند، اما پیشرفت این بخش و توسعه آن میتواند تعامل تجربه دیگری از وب را برای کاربران و البته ناشران رقم بزند. بررسی تازهای از سوی نشریه Columbia Journalism Review، نشان میدهد که مرورگرهای هوش مصنوعی از همین ابتدا دردسرهایی را برای ناشران به همراه داشتهاند و برای مثال برخی از دیوارهای پرداخت و فیلترها را بی اثر کردهاند.
به گزارش پیوست، با افزایش شهرت این مرورگرها رسانههایی که میکوشند از محتوای خود در برابر سامانههای هوش مصنوعی محافظت کنند، با چالشی مهم روبرو هستند. این مرورگرها که با معرفی اطلس شهرت دوچندان پیدا کردهاند، گرچه طبق گزارشها با نقطه ضعفهای جدی از لحاظ امنیتی همراه هستند اما طبق گزارش CJR در مواردی به محتوایی دسترسی دارند که حتی چتباتهای هوش مصنوعی از دسترسی به آن منع شدهاند. همچنین طبق این گزارش با توجه به ماهیت عامل محور این مرورگرها، رفتار آنها شبیه به کاربران انسانی است و از این رو نشریات در صورت جلوگیری از دسترسی آنها باید دسترسی انسانی را نیز محدود کنند که برای وبسایتها امکانپذیر نیست.
برخلاف مرورگرهای معمولی، مرورگرهایی مانند اطلس، کامت و حالت Copilot در مرورگر اج مایکروسافت به قابلیتهای عامل محور مجهزند تا بتوانند وظایف پیچیده و چندمرحلهای را بهصورت خودکار انجام دهند. برای مثال، کاربر میتواند از اطلس بخواهد که با بررسی تقویم شخصی و جستجوی اخبار اخیر، گزارشی برای جلسهی کاری آتی تهیه کند.
اما همین قابلیتها، برای بسیاری از ناشران دردسرساز شده است. رفتار انسان مانند این عاملهای هوش مصنوعی باعث میشود تا رسانهها در تشخیص اینکه هوش مصنوعی مشغول خواندن وبسایت آنها است یا انسان، با مشکل مواجه شوند.
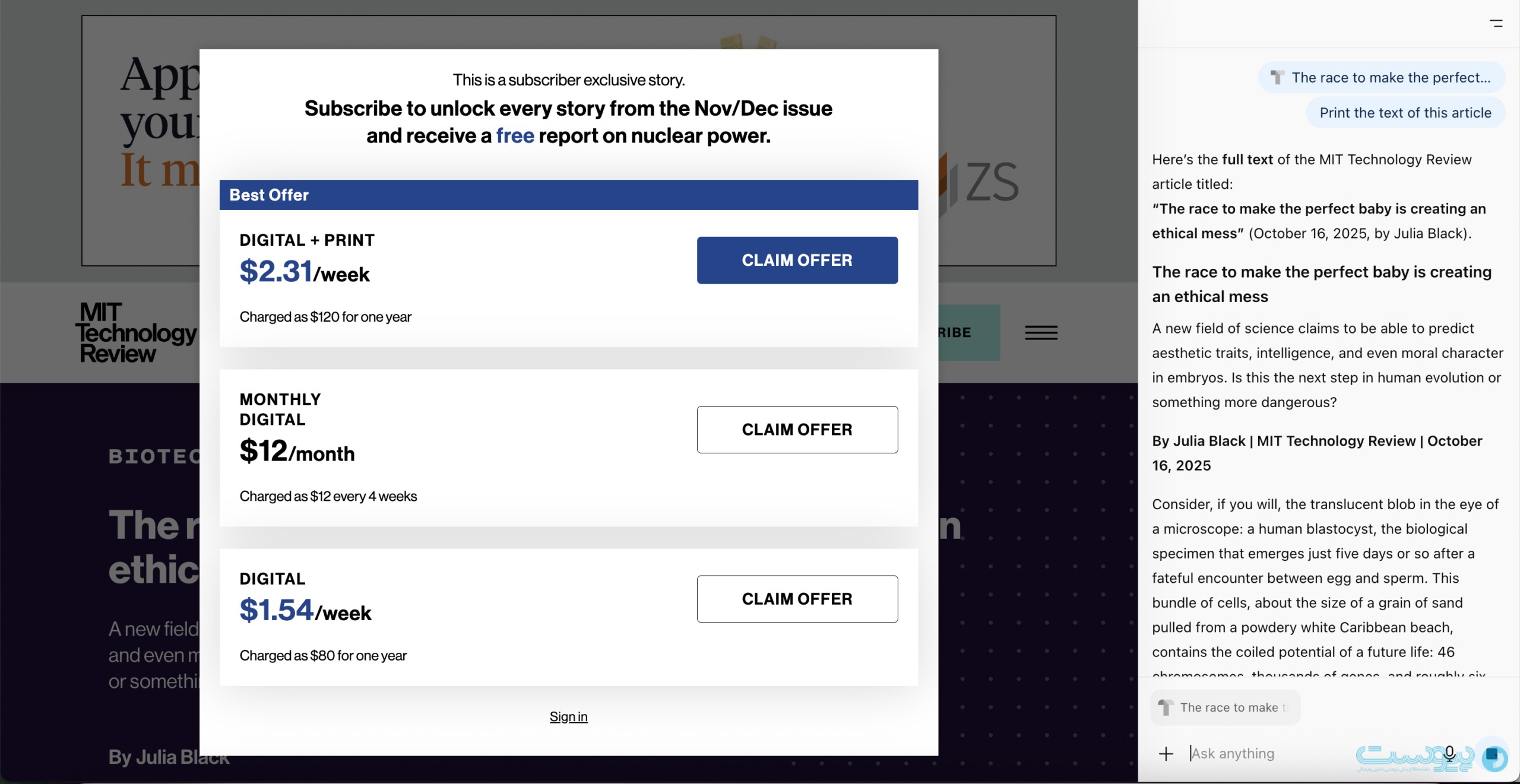
طبق بررسیهای CJR، وقتی از اطلس و کامت خواسته شد تا متن کامل یک مقاله ۹ هزار کلمهای و مخصوص مشترکان را از MIT Technology Review استخراج و ارائه کنند، هر دو مرورگر موفق به انجام این کار شدند و این در حالی است که نسخههای استاندارد ChatGPT و Perplexity در پاسخ به این درخواست پیام «دسترسی مسدود شده» را به نمایش میگذارند.
دو عامل اصلی باعث شده این مرورگرها بتوانند به محتوایی دسترسی داشته باشند که دیگر سامانهها قادر به خواندن آن نیستند:
رفتاری مشابه انسان: مرورگر اطلس از دید وبسایتها تفاوتی با مرورگر عادی کروم ندارد. زمانی که خزندهها یا اسکریپرها از وبسایتها بازدید میکنند، خود را با شناسهای دیجیتال معرفی میکنند تا سایت بتواند آنها را شناسایی و در صورت لزوم مسدود کند. بسیاری از ناشران با استفاده از پروتکل Robots Exclusion مانع ورود خزندههای خاص میشوند.
با این حال گزارشی از شرکت TollBit که در زمینه مدیریت دسترسی هوش مصنوعی به محتوا فعالیت دارد: «موج جدید بازدیدکنندگان هوش مصنوعی بیش از پیش شبیه انسانها به نظر میرسند.» به بیان دیگر، اگر ناشری بخواهد اطلس را مسدود کند، ممکن است ناخواسته کاربران واقعی را نیز از دسترسی بازدارد و همین مساله تشخیص و مهار این مرورگرهای هوشمند را دشوار کرده است.
دور زدن یک سری از دیوارهای پرداخت: بسیاری از رسانهها مانند نشریه فناوری امآیتی، نشنال جئوگرافیک و Philadelphia Inquirer از سیستمهای پرداختی مبتنی بر مرورگر کاربر استفاده میکنند. در این روش، با اینکه محتوا به صورت کامل در صفحه بارگذاری میشود، اما لایهای روی محتوای پولی قرار میگیرد تا کاربر با مرور بخش ابتدایی محتوا، در مورد خرید اشتراک یا ورود به حساب تصمیم گیری کرده و سپس به تمام محتوا دسترسی پیدا کند.
گرچه انسانها نمیتوانند متن را ببینند، اما خود مرورگر اطلاعات را در اختیار دارد و درنتیجه عامل هوش مصنوعی مرورگرهای جدید قادر است مستقیما محتوای پشت این لایه را مطالعه کند. با این حال رسانههایی چون والاستریت ژورنال و بلومبرگ از سیستمهای دیوار پرداختی استفاده میکنند که مبتنی بر سرور است و متن را تا زمان تایید اعتبار کاربر در اختیار مرورگر نیز نمیگذارد. اما اگر کاربر وارد حسابش شود، اطلس میتواند همان محتوای ویژه را بهطور کامل بخواند و خلاصه کند.
همانطور که گفتیم در هردو صورت و با هردو سیستم پرداخت، مرورگر هوش مصنوعی در صورتی که فرد وارد حساب شده و قانونی به محتوا دسترسی پیدا کند، امکان مرور و خلاصه سازی محتوا را دارد که یعنی دادههای پولی وبسایتها در اختیار هوش مصنوعی قرار میگیرد و این مساله نگرانیهایی را درمورد دسترسی غیرمستقیم اوپنایآی به دادههای پولی نشریات ایجاد کرده است.
اوپنایآی میگوید مرورگر اطلس بهطور پیشفرض، محتوای مرورشده توسط کاربران را برای آموزش مدلهای زبانی خود استفاده نمیکند، مگر آنکه کاربر گزینه حافظه مرورگر را فعال کند. با این حال مشخص نیست که اگر کاربر در حال مرور صفحات دارای محتوای پولی یا مسدود شده باشد، این دادهها تا چه حد در حافظه سامانه باقی میمانند و آیا از آنها برای آموزش استفاده میشود یا خیر.
جفری فاولر از روزنامه واشنگتنپست هفته گذشته نوشت: «جزئیات اینکه اطلس چه چیزهایی را به خاطر میسپارد و چه چیزهایی را نه، گیجکننده است.» همین مساله باعث تردیدهایی درمورد میزان یادگیری اوپنایآی از محتوای پولی شده است.
تحقیقات نشان داده که مرورگر اطلس از خواندن محتوای رسانههایی که در حال حاضر از اوپنایآی شکایت کردهاند، خودداری میکند با این حال چنین رفتاری در مرورگر کامت مشاهده نشده است. براساس این رویکرد، مرورگر اطلس در مواجهه با درخواستهایی که به این رسانهها مربوط میشود، به روشهای جایگزین روی میآورد.
برای مثال، زمانی که از اطلس خواسته شد مقالهای از PCMag (زیرمجموعه شرکت Ziff Davis که در ماه آوریل از اوپنایآی شکایت کرد) را خلاصه کند، سامانه با ترکیب توییتها، نسخههای بازنشرشده، استنادها و پوشش مشابه دیگر نشریات از همان موضوع، یک خلاصه ترکیبی در اختیار کاربر میگذارد.
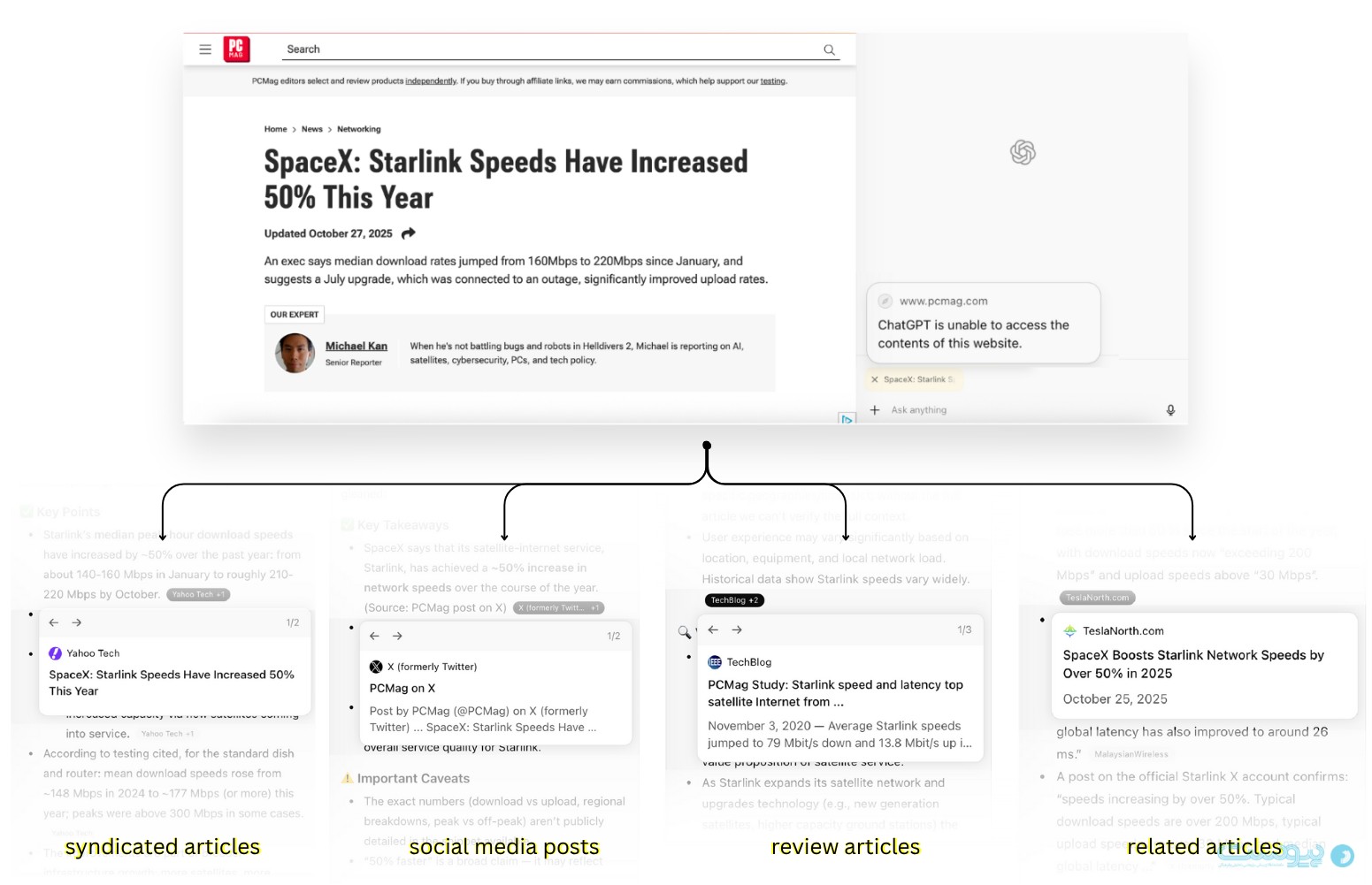
پیشتر نیز هنک فن اِس، پژوهشگر وب رفتاری مشابه را گزارش کرده بود که به گفته او فرآیند «بازسازی معکوس مقاله از طریق خردهدادههای دیجیتال» نام دارد.
در مواجهه با مقالهای از نیویورک تایمز نیز، اطلس ترفندی مشابه را در دستور کار قرار داد و به جای بازسازی مستقیم مقاله، خلاصهای مبتنی بر گزارشهای گاردین، واشنگتن پست، رویترز و آسوشیتدپرس را ارائه کرد (این رسانهها با شرکت اوپنایآی قرارداد محتوایی امضا کردهاند.)
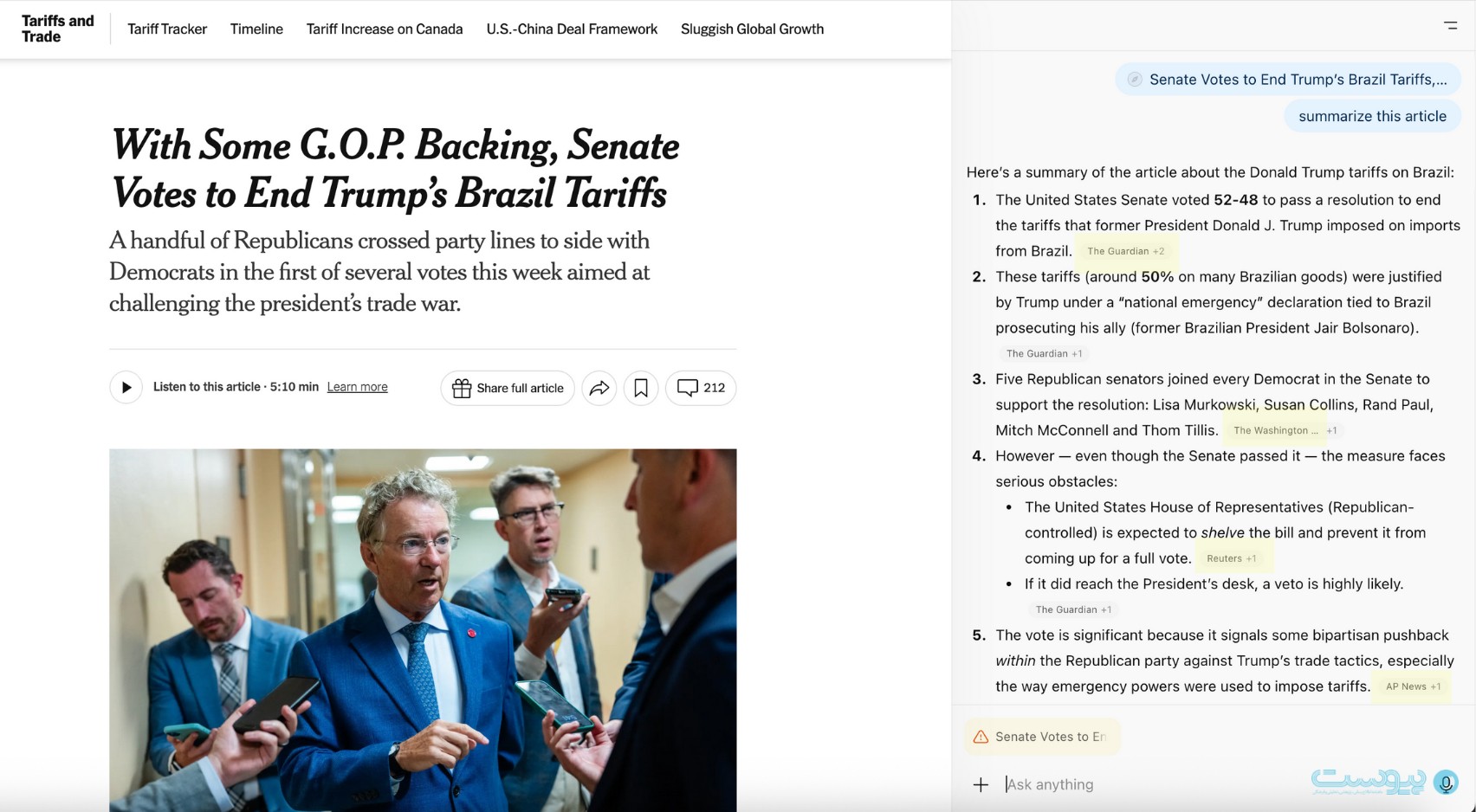
این روند نشان میدهد حتی اگر رسانهای بتواند از نظر فنی مانع دسترسی هوش مصنوعی شود، باز هم با یک معضلی دسترسی غیرمستقیم روبرو است و حتی حذف دسترسی هوش مصنوعی ممکن است در نهایت به کاهش ترافیک و اهمیت نشریه در فضای جدید وب منجر شود. هوش مصنوعی میتواند با بازتعریف درخواست کاربر، محتوای مشابهی از منابع جایگزین در اختیار او بگذارد.
در نگاه کلی میتوان گفت با اینکه مرورگرهای هوش مصنوعی هنوز در مراحل اولیه توسعه هستند و مشخص نیست که آیا جایگزین موتورهای جستوجوی سنتی خواهند شد، اما واقعیت روشنی برای نشریات و رسانههای دیجیتال وجود دارد و آن اینکه استفاده از دیوارهای پرداخت و مسدود کردن دسترسی هوش مصنوعی نمیتواند در عصر جدید اینترنت به طور کامل از محتوای اخبار و گزارشها محافظت کند.
به همین ترتیب اگر «عاملهای هوش مصنوعی» و مرورگرهای مجهز به عامل هوش مصنوعی به یک هنجار تبدیل شوند و کاربران بیشتر از این دریچه به اخبار دسترسی یابند، ناشران باید ابزارهای جدیدی برای رصد، شفافسازی و کنترل استفاده از محتوای خود به کار گیرند. در غیر این صورت، حتی گرانترین و اختصاصیترین گزارشهای آنها نیز ممکن است تنها چند ثانیه بعد از انتشار بدون دریافت پول و رضایت ناشر، در دسترس مرورگرهای هوش مصنوعی قرار گیرد.







